Claude Skill for GEO Audits: Your AI Search Presence Score and What to Do About It

Key Takeaways
- AI-referred visitors convert at 14.2% compared to traditional Google organic at 2.8%. The traffic volume is smaller, but the quality is dramatically higher.
- Google AI Overviews now appear in roughly 25% of searches, up 57% from late 2025.
- The GEO audit Skill runs five parallel subagent analyses (AI Citability, Platform Presence, Technical Infrastructure, Content Quality, Schema Markup) and produces a composite score out of 100.
- FAQ schema implementation is consistently the single highest-impact GEO improvement, moving scores by 8 to 12 points on average.
- Most B2B SaaS domains we audit score between 35 and 55 on their first assessment. The scoring distribution reveals which dimension to fix first.
- Running GEO audits on competitors, especially "dark horse" brands that appear in AI answers but do not rank organically, surfaces the exact tactics worth adopting.
That gap between traditional search visibility and AI search visibility is growing wider every quarter. The sites that show up in AI-generated answers are not always the ones that rank highest on Google. They are the ones with the right structural signals: clean schema, FAQ coverage, recent primary-source citations, and platform presence on the directories that AI models trust.
This guide walks through the five-subagent GEO audit Skill that scores any domain 0 to 100 on AI search readiness, breaks the score into five categories, and produces a prioritized action plan. We run this audit at the start of every client engagement and quarterly thereafter.
The AI Search Opportunity, by the Numbers
The data makes the case better than any argument.
Gartner predicts traditional search volume will decline 25% by 2026 as users move to AI answer engines. That prediction is tracking ahead of schedule. ChatGPT reached 900 million weekly active users in early 2025, and Perplexity, Gemini, and Copilot are adding users monthly.
AI referral traffic now represents 1.08% of total web traffic across industries, with IT and technology leading at 2.8%. Those percentages look small until you see the conversion data. AI-referred visitors convert at 14.2% compared to Google organic at 2.8%. That is a 5x conversion rate advantage.
The reason is intent quality. Someone asking ChatGPT "what is the best endpoint detection platform for mid-market companies" is further along the buyer journey than someone Googling "endpoint detection." The AI user is asking a specific, considered question. The answer they receive carries implicit recommendation weight.
Generative Engine Optimization is where SEO was in 2010. The opportunity is recognized. The first-mover window is closing. And most B2B SaaS brands have zero measurement of where they stand.
That is what the GEO audit fixes. It gives you a score, a breakdown by dimension, and a prioritized action plan.
For the foundational concepts behind Claude Skills, start with our complete guide. The GEO audit Skill is the most architecturally complex Skill type in our stack: five parallel subagents running independent analyses and feeding into a single composite score.
The Five-Subagent Architecture
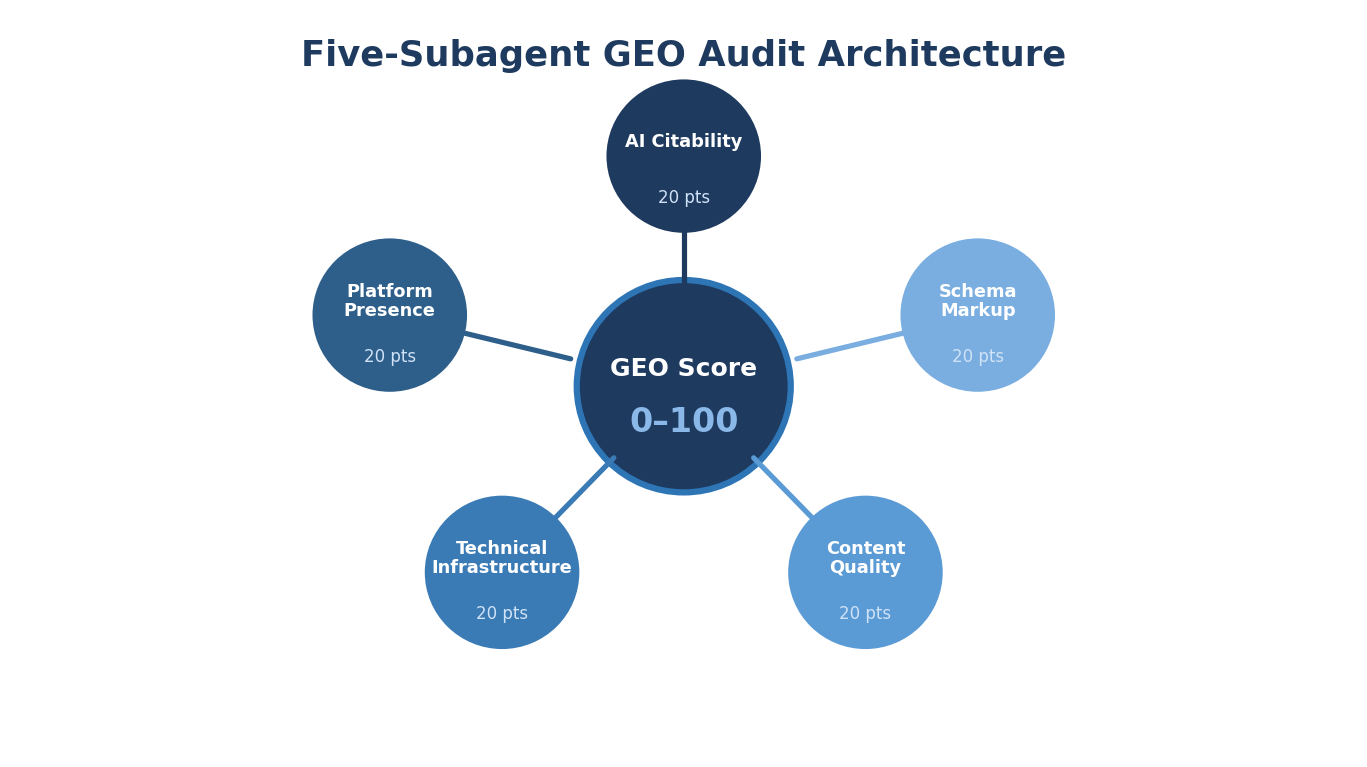
Each subagent runs independently in parallel, contributes 20 points to the composite score, and produces its own findings and recommendations. The parallel architecture means a full audit completes in 8 to 15 minutes (the time of the slowest subagent) rather than the 40 to 60 minutes a sequential architecture would require.
Subagent 1: AI Citability (20 Points)
This subagent answers the most basic question: does the brand show up in AI-generated answers?
It queries ChatGPT, Gemini, and Perplexity with 5 to 8 target queries relevant to the brand's category. For a B2B SaaS company selling project management software, the queries might include:
- "Best project management tools for remote teams"
- "Project management software comparison for enterprises"
- "What is the best alternative to Asana for mid-market companies"
- "How to choose project management software"
- "Top collaboration platforms for B2B teams"
For each query on each platform, the subagent checks:
- Mentioned: Is the brand name present anywhere in the response?
- Cited: Is the brand cited as a source, recommended, or listed in a comparison?
- Position: Where in the response does the mention appear (first paragraph, middle, end)?
- Competitor context: Which competitors are mentioned alongside the brand?
- Content type cited: What type of content gets referenced (product page, blog post, comparison, documentation)?
Scoring: A brand that appears on all three platforms for most queries scores 16 to 20. Appearing on one platform for a few queries scores 6 to 10. Zero appearances across all queries scores 0 to 5.
Subagent 2: Platform Presence (20 Points)
AI models draw from specific data sources beyond the open web. This subagent audits whether the brand has a presence on the platforms that feed those models.
Platforms checked:
- Wikipedia: Does the brand have a Wikipedia article? Is it well-sourced and current?
- Crunchbase: Is the company profile complete with current funding, headcount, and description?
- G2 and Capterra: Are review profiles active with recent reviews?
- LinkedIn Company Page: Is the company page complete with recent activity?
- Industry-specific directories: Depending on the vertical, this includes directories like BuiltWith (for tech), SecurityScorecard (for cybersecurity), or CB Insights (for fintech).
Each platform returns a status: Present / Missing / Needs Improvement. The "Needs Improvement" flag catches cases like a G2 profile that exists but has not been updated in 18 months, or a Crunchbase profile with a funding round missing.
Scoring: Complete, current presence across all platforms scores 16 to 20. Missing from two or more key platforms scores 6 to 10. No presence on G2, Capterra, or Wikipedia scores 0 to 5.
Subagent 3: Technical Infrastructure (20 Points)
AI crawlers need the same technical foundation as traditional search crawlers, plus a few AI-specific considerations. This subagent checks:
- Crawlability: Is robots.txt configured to allow AI crawlers (GPTBot, Google-Extended, ClaudeBot)? Is the sitemap complete?
- Page speed: Core Web Vitals scores for the top 10 pages by traffic. Slow pages get deprioritized in both traditional and AI search.
- HTTPS and mobile usability: Baseline signals that affect trust.
- Structured data presence: Does the site use JSON-LD structured data on key pages?
- Canonical tag correctness: Misconfigured canonicals cause AI models to cite the wrong URL or skip the content entirely.
- AI-specific headers: Does the site include meta tags that signal content permissions for AI crawling?
Scoring: Clean technical foundation with proper AI crawler access scores 16 to 20. Common issues (slow Core Web Vitals, missing sitemap entries, blocked AI crawlers) score 8 to 14. Major technical gaps (blocked crawlers, missing HTTPS, no structured data) score 0 to 7.
Subagent 4: Content Quality (20 Points)
This subagent evaluates the top 10 blog pages by traffic for AI citation readiness. The evaluation criteria are drawn from research on what AI models prefer to cite.
A study of 768,000 AI citations found that product specifications and comparisons dominate B2B AI answers at 70%, while standard blog posts earn under 6% of citations. The implication: content structure matters more than content volume.
Checks per page:
- FAQ coverage: Does the page include FAQ sections with concise, direct answers? FAQ-structured content is cited disproportionately by AI platforms, even when the surrounding article is long-form.
- Statistical accuracy: Are statistics current and attributed to primary sources? The fact-checking Skill feeds directly into this. Content with verified, primary-source citations performs measurably better in AI-generated summaries.
- Content comprehensiveness: Does the page cover the topic more thoroughly than ranking competitors? AI models prefer citing the most comprehensive source.
- Reading level and entity clarity: Is the writing clear enough for an AI model to extract factual statements? Convoluted prose with ambiguous entity references reduces citability.
Scoring: Pages with FAQ sections, current statistics, comprehensive coverage, and clear entity references score 16 to 20. Missing FAQ sections and thin content coverage score 8 to 14. Outdated statistics, no FAQ content, and below-competitor comprehensiveness score 0 to 7.
Subagent 5: Schema Markup (20 Points)
Schema markup tells AI models what the content is about, not just what it says. This subagent extracts all JSON-LD and microdata from the homepage and the top 5 blog pages.
Checks:
- Organization schema: Present and complete on the homepage? Includes name, URL, logo, sameAs links to social profiles?
- Article schema: Present on blog posts? Includes author, datePublished, dateModified?
- FAQPage schema: Present on pages with FAQ content? This is the single highest-impact schema type for GEO.
- BreadcrumbList schema: Present? Helps AI models understand site hierarchy.
- SoftwareApplication schema: Present on product pages? Critical for SaaS companies.
- HowTo schema: Present on tutorial and guide content?
The subagent also identifies which schema additions would most improve AI Overview eligibility. Google's AI Overviews draw heavily from pages with structured data, especially FAQPage and HowTo schema.
Scoring: Comprehensive schema across all page types scores 16 to 20. Partial implementation (Organization only, no FAQPage) scores 8 to 14. Missing structured data entirely scores 0 to 7.
Concrete Walkthrough: What a 47/100 Score Looks Like
We ran the GEO audit on a mid-market B2B SaaS company selling workflow automation software to operations teams. They had strong traditional SEO: 85 page-one rankings, 18,000 organic visits per month, domain authority of 52.
Their GEO score: 47/100.
Here is the breakdown:
The score reveals the story. This company has decent technical infrastructure and some platform presence, but their content is not structured for AI citation (no FAQs, no comparisons, outdated sources), their schema is minimal, and AI models cannot crawl most of their site due to a robots.txt block.
The Prioritized Action Plan
The GEO audit produces a two-tier action plan: Quick Wins (implementable within 1 to 2 weeks) and Strategic Investments (require 1 to 3 months).
Quick Wins for this client:
- Remove GPTBot block from robots.txt. Estimated score impact: +3 to 5 points on Technical Infrastructure. This is a 5-minute configuration change that immediately allows AI models to access the site's content.
- Add FAQPage schema to top 10 blog posts. Estimated score impact: +8 to 12 points across Schema Markup and Content Quality. This is consistently the single highest-impact GEO improvement we recommend.
- Update G2 and Crunchbase profiles. Estimated score impact: +3 to 4 points on Platform Presence. Stale profiles signal to AI models that the company data may be outdated.
- Add Organization schema sameAs links. Connect the homepage Organization schema to LinkedIn, Twitter, G2, and Crunchbase profiles. Estimated score impact: +1 to 2 points on Schema Markup.
Strategic Investments:
- Create FAQ content sections on all high-traffic pages. Write 5 to 8 FAQ answers per page using actual search queries from keyword research. Estimated score impact: +5 to 8 points on Content Quality over 2 months.
- Build comparison content. Create competitor comparison landing pages for the top 5 competitors. Product comparisons earn 70% of B2B AI citations. Estimated score impact: +4 to 6 points on AI Citability over 3 months.
- Run fact-checking on all published content. Update outdated statistics with current primary sources. This improves both Content Quality and AI Citability, because AI models prioritize accurately sourced content. The fact-checking Skill handles this at scale.
- Develop a Wikipedia presence. For brands with sufficient notability, a Wikipedia article is a high-value platform signal. This requires meeting Wikipedia's notability guidelines with independent reliable sources.
FAQ Schema: The Highest-Impact Single Improvement
FAQ schema deserves its own section because it consistently produces the largest GEO score increase per unit of effort.
Before:
A blog post about "How to Choose Workflow Automation Software" has a section at the bottom with questions and answers, formatted as regular H3 headings and paragraph text. AI models read this as regular content.
<h3>How much does workflow automation software cost?</h3>
<p>Workflow automation software typically costs between $10
and $50 per user per month for mid-market solutions, with
enterprise pricing starting at $100+ per user.</p>
After:
The same content, with FAQPage schema added:
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "How much does workflow automation software cost?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Workflow automation software typically costs
between $10 and $50 per user per month for mid-market
solutions, with enterprise pricing starting at $100+
per user."
}
}
]
}
The content is identical. The user experience is identical. But the structured data tells AI models exactly what the question is and exactly what the answer is, making it trivially easy to cite in a generated response.
Google deprecated FAQ rich results from traditional search in 2023, which led many teams to remove FAQ schema entirely. That was a mistake. AI models, including Google's own AI Overviews, still use FAQPage schema as a strong signal for identifying citable question-answer pairs. The rich result is gone, but the AI citation benefit remains.
Running GEO Audits on Competitors
The Skill works on any domain, not just your own. Running the GEO audit on three to five competitors produces a competitive GEO landscape that reveals exactly where the opportunity gaps are.
Here is the playbook we run for every new engagement:
- Audit the client domain. Establish the baseline score.
- Audit the top three organic competitors. The brands that rank for the same keywords in traditional search.
- Audit one or two dark horse competitors. This is where it gets interesting.
The Dark Horse Concept
A dark horse competitor is a brand that shows up frequently in AI-generated answers but does not rank well in traditional organic search. They are invisible in standard SEO competitive analysis but highly visible in AI search.
We discovered this pattern while auditing a cybersecurity SaaS client. Their traditional competitors (the brands ranking for the same keywords) scored between 38 and 52 on the GEO audit. Expected range.
But when we checked which brands appeared in AI answers for the client's target queries, a smaller company kept showing up. This company ranked outside the top 20 organically for most of the target keywords. Their domain authority was lower. Their backlink profile was weaker.
Their GEO score: 71/100.
The breakdown revealed why. They had FAQPage schema on every blog post. Every statistic cited a primary source with a publication date. Their product pages used SoftwareApplication schema with complete feature descriptions. Their G2 profile had 200+ reviews updated monthly. And their robots.txt explicitly allowed all AI crawlers.
They had optimized for AI citation while their competitors optimized for traditional ranking. In a market where AI referral traffic converts at 5x the rate of organic, that positioning was deliberate and effective.
The dark horse's tactics became the client's GEO improvement roadmap. FAQ schema, primary source citations, complete structured data, active platform profiles. These are not expensive or technically difficult changes. They are the changes that nobody makes because they are not visible in traditional SEO metrics..
Connecting GEO Audits to the Skill Stack
The GEO audit is a diagnostic. Other Skills in the stack close the gaps it identifies.
- Low Content Quality score feeds into the content brief Skill. New content gets structured for AI citability from the brief stage, with FAQ sections, primary source requirements, and entity clarity baked into the writing instructions.
- Low Schema Markup score triggers a schema generation workflow. The GEO audit identifies which pages need which schema types. A downstream Skill generates the JSON-LD and implements it.
- Outdated statistics flagged in Content Quality feeds into the fact-checking Skill. Every outdated claim gets verified, corrected, and updated with a current primary source.
- Poor internal linking patterns identified in Technical Infrastructure connect to the internal linking Skill. Strong internal linking builds the topical authority signals that AI models use when evaluating content credibility.
- Missing platform presence gets escalated to the marketing team for manual action. Creating a Wikipedia article or completing a G2 profile requires human effort, not automation.
The audit is the starting point. The Skill stack is the execution plan. Run the audit quarterly to measure progress and re-prioritize.
For teams focused specifically on ranking in ChatGPT, the AI Citability subagent alone provides actionable intelligence. Which queries trigger a mention? Which competitors appear instead? What content type gets cited most frequently? Those answers shape the content strategy for the next quarter.
TripleDart's GEO audit Skill delivers a full composite score, five-dimension breakdown, and prioritized action plan in under 20 minutes for any domain. We run it at the start of every client engagement, on the client's competitors, and on the dark horse brands that appear in AI answers.
The audit connects directly to our fact-checking, internal linking, content brief, and schema generation Skills so every identified gap has a clear path to resolution.
Book a meeting with TripleDart to see your current GEO Score and get the prioritized action plan.
Try Slate here: slatehq.com
Frequently Asked Questions
How long does the five-subagent audit take?
With parallel execution, 8 to 15 minutes for the subagent analyses plus 2 to 3 minutes for score synthesis and action plan generation. Under 20 minutes total. The AI Citability subagent is usually the slowest because it queries three AI platforms with multiple prompts each.
How often should the GEO audit run?
Baseline at engagement start, then quarterly. AI citation patterns change as models are updated (major model releases happen every 3 to 6 months), and your content changes between audits. Quarterly cadence captures both model-side and site-side changes.
What is the single highest-impact GEO improvement?
FAQ schema implementation, consistently. It is a low-effort, largely one-time change per page that moves GEO scores by 8 to 12 points on average. The implementation is straightforward (JSON-LD added to the page template), and the impact is measurable within one audit cycle.
Can I run the audit on competitor domains?
Yes. The Skill works on any publicly accessible domain. Replace client-specific instructions with third-party analysis configuration. The output shows exactly where competitors are well-positioned for AI search and where they have gaps you can exploit.
How does GEO relate to traditional SEO?
Correlated but distinct. A page can rank on page one of Google and never appear in an AI answer if it lacks structured data, FAQ content, and primary-source citations. Conversely, a page outside the top 20 organically can appear in AI answers if it has the right structural signals. The good news: most GEO improvements (schema, FAQ structure, source citations, clean technical infrastructure) also improve traditional SEO performance.
Which AI platforms matter most for B2B SaaS?
ChatGPT dominates referral traffic volume. Perplexity leads on citation density (it cites sources more frequently than other platforms). Google AI Overviews reach the broadest search audience at 25% of queries. The GEO audit checks all three.
Does GEO optimization hurt traditional SEO?
No. Every GEO improvement we recommend either benefits traditional SEO directly (schema, page speed, content comprehensiveness) or has zero negative impact (platform presence, AI crawler access). There is no tradeoff. The investment compounds across both channels.
What is the ROI measurement for GEO?
Track AI referral traffic in analytics (note: AI traffic is often misattributed as "direct" in Google Analytics, so configuring proper UTM tracking for AI platforms is important). Monitor brand mentions in AI responses using the AI Citability subagent quarterly. Compare GEO scores quarter over quarter. At 14.2% conversion rates, even small increases in AI referral traffic produce measurable pipeline impact.
How does the GEO audit connect to other Skills in the stack?
The GEO audit identifies gaps. Other Skills close them. Low Content Quality scores feed into the content brief Skill. Low Schema scores trigger schema generation. Citation gaps feed into the fact-checking Skill. Poor internal link structure connects to the internal linking Skill. The audit is the diagnostic. The Skill stack is the treatment plan.
.png)
summarize with ai




