.png)
.png)
Key Takeaways
- Most Claude content workflows fail not on the prompt, but on what the writer gives Claude before the prompt and what the editor does to the draft after.
- The brief carries about 70% of the draft quality. We ship a 12-section brief format that locks reader, angle, SERP context, and anchor claim before a single word gets generated.
- A writing CLAUDE.md file solves the voice-drift problem that defeats most teams by the third article. Every rule in our file maps to a specific failure we watched happen.
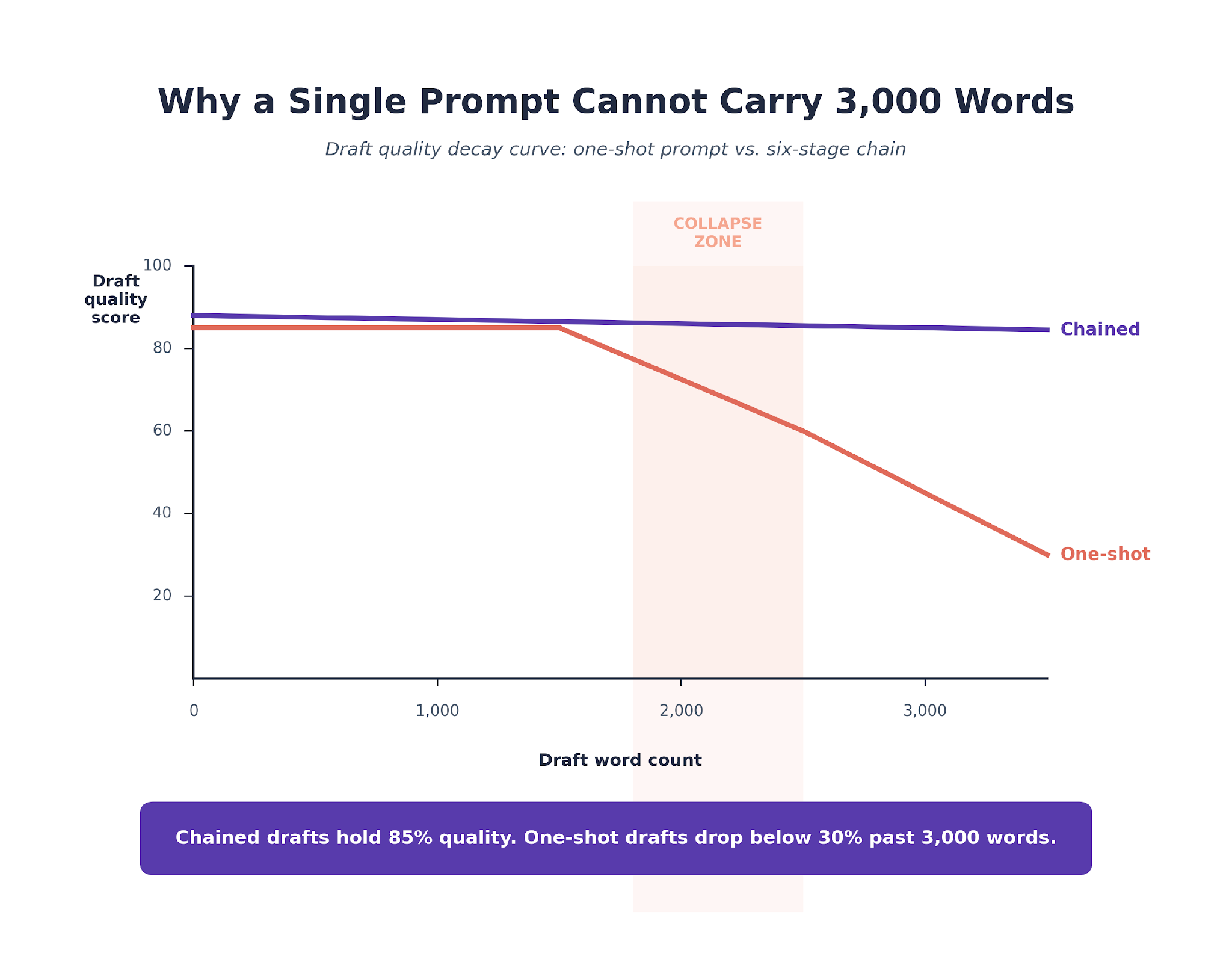
- We run drafting as a six-stage prompt chain, not one giant prompt. Single-prompt drafts collapse past 2,000 words. The chain holds voice and structure to 3,500.
- Editors still rewrite roughly 90% of sentences before publish. The 70/10 rule holds: 70% of information survives, 10% of sentences survive verbatim.
- The unlock is not Claude. It is the setup around Claude. Teams that copy our prompt chain but skip the brief and CLAUDE.md discipline see no durable quality lift.
Why Most Claude Content Drafts Read Fluent But Never Ship
The draft comes back in four minutes. It is 2,600 words. It hits the word count, the heading outline, the keyword variants the writer asked for.
Read it out loud and it sounds like content. Read it twice and you notice that nothing in it is wrong, nothing in it is insightful, and nothing in it is specifically yours.
That is the gap we built our workflow to close. We have rebuilt our writing pipeline around Claude four separate times in the last 18 months.
Every rebuild sharpened the same conviction. The problem is almost never the prompt. The problem is what you hand Claude before the prompt and what you do with the draft after.
This article is the pipeline we run today. The one that ships SEO content across B2B SaaS engagements at TripleDart every week.
Our full agency Claude workflow sits across all seven stages of what we do. This piece is the content layer in depth, the one our writers and editors touch every day.
We will work through it the same way a content lead would if they sat down at 9 AM to ship an article by end of Wednesday.
The Brief Carries Seventy Percent of the Draft Quality
You can tell the brief from the draft. A content lead who has been shipping with Claude for a quarter can read a first draft and tell you which sections of the brief the writer skipped.
Missing angle gets you a draft that reads generic. Missing competitor wedge gets you a draft that mirrors the number-one ranking piece. Missing anchor claim gets you a draft that summarizes the SERP instead of beating it.
The brief is where draft quality is decided. Not the prompt, not the model, not the temperature setting.
We run a 12-section brief on every piece we ship. The sections that get skipped map cleanly to the failures we see in the draft.
The content brief template we publish covers the core structure if you want to start without the full 12-section build.

Building a good brief takes 10 to 15 minutes once the research phase is done. Building a lazy one takes 90 seconds.
The difference in the draft is not 10 to 15 minutes. It is closer to two hours of editor time saved on the back end, and sometimes the difference between a piece that ranks and one that dies.
Our keyword research workflow feeds sections 1, 2, 6, and 12 of the brief directly. The brief work starts where the keyword work ends.
Sections Three, Five, and Nine Get Skipped Most
Writers skip the angle because "let's see what Claude comes up with" feels like flexibility. It is delegation to a model that has no opinion on what your piece should own.
Writers skip the SERP structure because it feels like a formality. It is the single biggest driver of whether Claude produces a listicle when the SERP rewards how-tos.
Writers skip the anchor claim because it is the hardest 20 minutes of the brief. It is also the one thing that separates your piece from the four that already rank.
The Brief Quality Pattern We Keep Seeing
Briefs that hit all 12 sections produce drafts where editors add the expert layer in under 45 minutes. Briefs missing sections 3, 5, or 9 produce drafts that get rebuilt from the ground up. Across the SaaS content programs we run, the correlation is not subtle. Brief completeness predicts editor rewrite volume more reliably than any other input we have measured.
The brief is the cheapest place to fix quality. It is also the most skipped. Every content team we have worked with that was unhappy with their Claude output was cutting corners here first.
The deeper framing on why the brief carries most of the quality decision is covered in our content brief process piece.
CLAUDE.md Is Where Voice Gets Enforced
The brief solves what Claude writes about. CLAUDE.md solves how Claude writes it.
A CLAUDE.md is a system-level instruction file that lives in the Claude Code project directory. Claude reads it automatically every session and applies the rules across every prompt the writer runs.
For us, it is the difference between a draft that sounds generic and a draft that sounds like the client brand.
We run a three-layer stack: an agency-wide file for standards, a client file for voice and positioning, and a task file for the specific job. The writing task file is the one writers touch most. It looks like this.
Every Rule in the File Has a Story
The "no em dashes" line came from an audit where we realized 40% of the em dashes in our draft had been introduced by Claude at the polish stage. They had sailed through six editor passes.
The banned phrases list grew one phrase at a time. Each one added after we caught it in a shipped draft and traced it back.
The entity rule, maybe the strictest one in the file, came from the day Claude inserted a competitor product we do not use into a client's pricing-page copy. Three editors missed it.
The CLAUDE.md rule is now non-negotiable across every content engagement we run.
Why Voice Failures Are Patterned, Not Random
The voice failures Claude produces are not random. They are patterned.
Model training reinforces certain cadences that read smooth but land generic. The scene opener, the rule-of-three staccato, the negation-then-affirmation pivot, the "in an era where" filler.
Once you can name them, you can ban them at the CLAUDE.md layer. Once you ban them, editors stop seeing them. That is the payoff on keeping the file strict.
Writing without this file is the state most Claude content teams never leave. They ship a great first article, a pretty good second one, a drifting third one.
By the fifth the voice has quietly diverged from the client's brand so much that the next client review meeting becomes uncomfortable. The CLAUDE.md is what stops that drift before it starts.
The Six-Stage Prompt Chain Holds 3,000 Words Together
Brief locks what. CLAUDE.md locks how. Neither of them solves the mechanical problem of producing 3,000 coherent words in the client's voice without the piece collapsing in the middle.
Single-prompt drafts start fine. They drift at 1,800 words and go fully off-voice at 2,500. We watched this happen enough times that we rebuilt drafting as a chain.
Six prompts, each with a narrow job. The chain runs in 18 to 22 minutes for a 3,000-word piece. Writers review between each stage.
Stage 1. Scaffold the Outline
Prompt one ingests the brief and returns a full outline. H1, deck, Key Takeaways, body H2s with direct-answer leads, H3 placement, FAQ questions, the anchor claim per section.
The writer reviews and rejects outlines that duplicate competitor structure. This is the single most common place to catch a drift early.
An outline that reads like the number-one ranking piece will produce a draft that reads like the number-one ranking piece.
Stage 2. Elaborate the Body Sections
Prompt two expands every body H2 into prose. Section by section, not all at once.
We ask Claude to hold the 30 to 60 word direct-answer lead on every H2 and to carry the thread between sections using the article's narrative device.
Writing section by section is slower by about three minutes. It avoids the 2,500-word collapse that a single-prompt draft produces. The Search Engine Land guide makes the same case from the data-analysis angle.
Stage 3. Pressure-Test Every Claim
Prompt three reads back the draft with one instruction. Flag every sentence that makes a factual claim without a supporting source.
Unsupported claims get tagged. The writer then either resolves from the brief's source list or cuts the claim.
This stage is where 60% of hallucinations get caught before they reach the editor.
Stage 4. Cite the Primary Sources
Prompt four pulls in the external sources from brief section 11 and places them inline with 2 to 4 word anchor text.
The writer verifies the links against the source list. New candidates from Claude are allowed, but no URL ships without the writer confirming it resolves.
Stage 5. Compress the Prose
Prompt five runs a readability pass. Every sentence over 28 words gets split or rewritten as a list.
Paragraphs over three rendered lines get broken. Em dashes get replaced. Banned phrases get flagged for rewrite.
This stage alone removes about 15% of surface-AI voice.
Stage 6. Polish the Voice
Prompt six is the house-voice pass. The whole draft gets read against the client CLAUDE.md.
Anywhere the voice drifts, generic filler, try-hard rhetorical questions, recycled LinkedIn phrasing, Claude rewrites to spec.
Any first-party agency observation required by the brief gets woven in here.
Why the Chain Beats the Single Prompt
The chain is boring to describe and surprisingly effective to run. Watching it on a piece you care about is what makes it non-negotiable.
The prompts themselves live in our daily SEO prompt library where we break down the 15 we run across the full SEO workflow.
What Our Content Engine Data Shows
Across the SaaS content programs we run, the six-stage chain produces drafts that pass editor fact-check on first read about 85% of the time. Single-prompt drafts on the same briefs pass first-read fact-check closer to 55%. The delta is almost entirely in stages 3 and 4, where claims get pressure-tested and sourced before the writer ever sees the draft.
The Editor Pass Is Where the Piece Becomes Publishable
All that scaffolding produces a first draft. Not a publishable one.
There is a long list of things Claude cannot credibly do without a human in the loop. The editor pass is where that list gets handled.
We do not publish Claude drafts. We publish drafts Claude wrote and editors rebuilt.
Five Things Editors Own End to End
The first is insider examples from client engagements. A line like "the integrations team shipped a rewrite of the template in one release and the impression line ticked up by day three" cannot be produced by a model.
The second is specific numbers that land in context. Usually the kind a client shared in passing and the editor remembered.
The third is proprietary frameworks we invented and named. The fourth is the insights pulled from customer or stakeholder interviews.
The fifth is the one sentence that decides whether a reader remembers the piece. Everything else Claude can scaffold.

The Editor Checklist Runs Four Stages
Fact check runs 10 to 15 minutes. Expert layering runs 20 to 30. Voice polish runs another 10 to 15. Final pass runs 10.
Expert layering is the longest. This is where editors pull in the client interview quotes, the specific numbers, the examples only someone who has done the work can produce.
Voice polish is the stage where Claude's residual LinkedIn cadence gets scrubbed. Total editor time per 3,000-word piece sits at 50 to 70 minutes.
The Ratio Is the Unlock
Before Claude, a 3,000-word piece ran four to six hours of writer time end to end.
After Claude, the same piece runs 18 to 22 minutes of writer time and 50 to 70 minutes of editor time. Output per content lead roughly doubled without quality loss.
The caveat is that teams already understaffed on editing did not fix the problem by adding Claude. Claude doubled writer output, which doubled the editor bottleneck.
Adding editor capacity first and Claude second is the order that works. The order most teams try is the opposite, which is why most teams plateau on quality before they plateau on volume.
Teams that bring us in to run their SaaS content engine hit the editor-first rhythm in month two.
Red Flags Editors Never Let Through
Sentences describing the reader's emotional state ("frustrated," "overwhelmed") are always Claude, always cut.
Statistics without a linked primary source get queried. Hypothetical company examples get flagged unless labeled as such.
Any claim that could be traced back to TripleDart results gets fact-checked against the engagement data before it ships.
The Ahrefs research on 600,000 AI-assisted pages backs what we see in production. AI content ranks when it is layered, and stops ranking when the expert layer is skipped.
Our own AI-assisted content breakdown frames the distinction clients get wrong most often, between pure generation and the layered workflow that ranks.
The HubSpot study of 300+ web strategists reaches a similar read from a different dataset.
The Editor Time Pattern Across Our Content Engines
Editor time per 3,000-word article sits at roughly 55 minutes on average across the SaaS content programs we run today. The programs with the best ranking outcomes are also the ones where editor time is highest. The correlation is not subtle. Teams that cut editor time to 20 minutes per piece to publish faster always pay for it in ranking regressions within the next two quarters.
Putting It Together on One Live Piece
Here is what the pipeline looks like when it runs. A DevOps observability engagement, target keyword "alert fatigue engineering teams," commercial-informational intent.
Monday: Brief and Outline
The content lead pulled SERP data, competitor URLs, and reader research in 28 minutes. Three ranking competitors, all definitive-guide pieces, all giving the reader the same advice.
The angle wedge in brief section 3 turned into "what alert fatigue looks like on the SRE team, not on the SRE blog." Section 9 locked the anchor claim: "most alert fatigue posts treat it as a tooling problem; it is a thresholding problem."
Brief done in another 14 minutes. Total brief time: 42 minutes.
Monday afternoon, stage 1 produced a 14-section outline. The content lead rejected three H2s that mirrored the number-one ranking piece, merged two H3s, and approved the rest in 11 minutes.
Tuesday: Draft and Edit
Tuesday morning, stages 2 through 5 ran in sequence and produced a 3,100-word draft.
Stage 3 flagged four unsupported claims. The writer resolved two from the brief and cut two. Total writer time Tuesday: 19 active minutes.
Tuesday afternoon, the editor pass. Voice polish ran through the CLAUDE.md in 6 minutes.
The editor pass itself took 63 minutes. Two SRE anecdotes pulled from a client interview, a reworked opening paragraph, 11 sentence-level voice rewrites, two H3 inserts where Claude produced generic content.
Wednesday: Publish
Wednesday morning, 9:14 AM, the piece went live.

Ninety days later, the page ranked number four for the primary keyword. It had picked up 17 referring domains organically and was showing up in ChatGPT responses for three related queries.
It became the top-performing article in the client's content portfolio for the quarter.
Total time from brief to publish: 2.5 working hours across writer and editor. Pre-Claude equivalent on the same piece would have been seven to nine hours.
What Our Tracking Shows on This Piece
The article picked up AI citations inside the first 30 days across three engines. TripleDart data on SEO content across the same window shows that AI citations land earlier and more frequently on pieces structured to answer the direct question in the first paragraph of every section. The six-stage chain enforces exactly that structure, which is not coincidence. How we track the AI citation layer alongside traditional search sits in our client reporting workflow.
Putting the Workflow Into Practice
The workflow above is not complicated. It is disciplined.
The brief takes 10 minutes longer than writers want to spend. The CLAUDE.md takes a week to build and six months to refine. The prompt chain takes six minutes longer than one giant prompt would.
The editor pass is an hour we cannot compress further without losing what makes the piece ship-ready.
The gains stack because every piece of the setup makes the next one faster. The brief template is reused. The CLAUDE.md gets sharper with every banned-phrase addition.
The prompt chain runs the same way every time. The editor checklist becomes muscle memory.
What looks like a careful process on piece one looks like a production line by piece 20.
We run this stack across 250+ B2B SaaS engagements at TripleDart. The pattern carries across WeWork, Atlas, Payoneer, and SignEasy, and across verticals that share almost nothing structurally.
The broader frame for how content fits with SEO, AEO, and paid sits in our AI SEO playbook. The content-specific service page is our SaaS content writing primer.
To see how it would run on your content program, talk to our team.
Frequently Asked Questions
How much of a Claude-written article gets rewritten before publish?
About 90% of sentences get rewritten in the editor pass, though roughly 70% of the information survives. The information survival is where the time savings come from. Claude does the assembly work in 20 minutes; the editor spends 60 minutes adding the expert layer.
Can Claude replace an SEO content writer?
No. Writers who know their topic deeply are the ones who catch Claude's drift and layer in the insight Claude cannot produce. Teams that remove the writer layer produce drafts that rank briefly and lose authority over time. The pattern is consistent across the engagements we have watched try it.
Which Claude model is the best fit for SEO content?
We default to Claude Opus for drafting and voice polish. The instruction-following precision carries more weight on long-form SEO than raw speed. For research summarization and outline scaffolding, Claude Sonnet is usually enough. Anthropic's Claude model overview covers the current tier differences.
How do you stop Claude from hallucinating in a content draft?
Three guards, stacked. The brief locks the entity list so Claude cannot introduce random products. Stage 3 of the prompt chain flags unsupported claims. Every draft gets an editor fact-check before publish. Hallucination still happens occasionally; the layered guard catches it.
Does AI-written content really rank?
AI-assisted content ranks when it is layered with human expertise. Pure AI output ranks briefly and loses position as Google improves at detecting generic prose. The two studies cited above reach the same conclusion from different datasets; Ahrefs' AI SEO statistics compilation adds more recent data on the pattern.
Claude Projects or Claude Code for content work?
Both. Claude Projects for quick one-off pieces where the CLAUDE.md files live inside the project UI. Claude Code for large content engines where the brief, the CLAUDE.md stack, and the prompt chain all live on the filesystem and get versioned. Most of our team runs Claude Code day-to-day.
How do you hold brand voice consistent across many writers? The writing CLAUDE.md is the source of truth. Every writer runs against the same file, and updates propagate to every draft on the next run. Without that discipline, voice drifts within three articles. We carry the same pattern across our AI marketing workflows for non-content work too.
Can Claude write the brief as well as the draft? It can draft a brief from a target keyword in about two minutes. The reader section, the angle wedge, and the anchor claim need human research to be any good. Using Claude to draft the brief and a human to finish it is the most common workflow we run.

.png)




.webp)

















.webp)





.webp)


.webp)
.png)







%20(1).png)



.webp)
.webp)
.webp)





%20Ads%20for%20SaaS%202026_%20Types%2C%20Strategies%20%26%20Best%20Practices%20(1).webp)







.webp)
















.webp)









![Creating an Enterprise SaaS Marketing Strategy [Based on Industry Insights and Trends in 2026]](https://cdn.prod.website-files.com/632b673b055f4310bdb8637d/6a218bacea463474377dfd32_34%20-%20Creating%20an%20Enterprise%20SaaS%20Marketing%20Strategy.png)



















































.webp)














%20Agencies%20for%20B2B%20SaaS%20Compared%20(2026).webp)

.webp)

%20with%20Hubspot.webp)


_%20Expert%20Reviews%20%26%20Comparisons.png)












.webp)

















_%20Comparison%2C%20Strengths%2C%20and%20How%20to%20Choose.png)

















.webp)




.webp)




.webp)













































%20Tools%20in%202026_%20Vetted%20List.webp)





![How to Measure AEO Success: 12 Metrics Beyond Clicks [2026 Framework]](https://cdn.prod.website-files.com/632b673b055f4310bdb8637d/6a0d664b326187e99b3d5960_6%20-%20The%20Ultimate%20Guide%20to%20Measuring%20AEO%20Success%20in%202026.png)
![7-Step Workflow for AEO-Ready Content [2026 Framework]](https://cdn.prod.website-files.com/632b673b055f4310bdb8637d/6a0d55ea88913ede1d3a7123_5%20-%20Workflows%20for%20Optimized%20AEO-Ready%20Content%20Creation.png)
.png)

![How to Structure Content for AEO and GEO [With Templates]](https://cdn.prod.website-files.com/632b673b055f4310bdb8637d/6a0c6a56eb700472e635ff33_1%20-%20How%20to%20Structure%20%20Content%20for%20AEO%20and%20GEO%20%20Summaries%20(2026).png)








.png)

























.webp)


%20Agencies%20in%202027.webp)
.webp)
![Top 9 AI SEO Content Generators for 2026 [Ranked & Reviewed]](https://cdn.prod.website-files.com/632b673b055f4310bdb8637d/6a2a3e3105bc1a127aae4e8e_34%20-%20Top%209%20AI%20SEO%20Content%20Generators%20for%202026%20%5BRanked%20%26%20Reviewed%5D.webp)






























