.png)

Key Takeaways
- Screaming Frog is still the crawler. Claude is the analyst. The combination compresses a two-day audit into about six working hours without losing depth.
- Raw crawl exports sit in the project folder. Claude Code reads them through the filesystem MCP. No copy-paste, no spreadsheet gymnastics.
- Five prompts carry most of the reasoning work: orphan detection, redirect chain hygiene, duplicate pattern surfacing, crawl depth outliers, and schema gap mapping.
- The lift is pattern recognition, not issue counting. Claude groups the 847 duplicate H1s into the three URL patterns that contain 812 of them. That is where the time savings and the quality gain stack up.
- Three checks stay human-only every audit: rendered-HTML validation, canonical logic on high-value URLs, and any change that could move a ranking signal.
- Audits feed ranking recoveries when engineering ships the findings the same quarter. We watched an /integrations/ template fix recover 290,000 monthly impressions in six weeks.
Why Crawler-Only Audits Leave Half the Insight on the Table
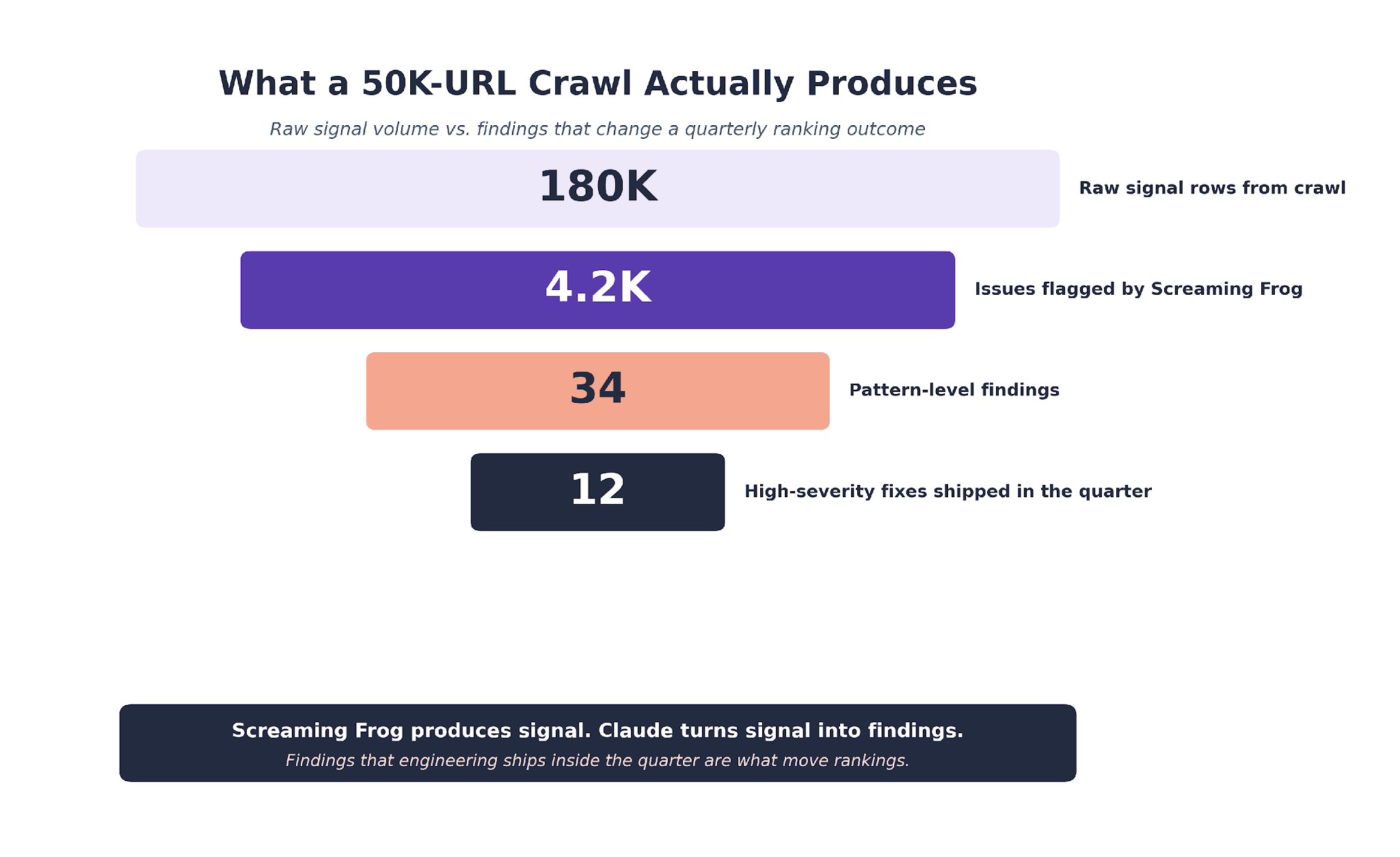
A Screaming Frog crawl of a 50,000-page B2B SaaS site produces roughly 180,000 rows of signal. Every issue is flagged correctly. None of them tell you which 12 findings matter this quarter.
That last step used to take a senior technical SEO a full day of spreadsheet filtering. The work was tedious, error-prone, and mostly pattern-matching that a human brain gets worse at after two hours of staring at CSV data.
Claude picks up exactly where the crawler stops. It reads the same exports, holds the full graph in context, and reasons across rows the way an analyst would if they had infinite patience.
This is the pipeline we run across B2B SaaS engagements at TripleDart. The one that lets a technical SEO lead audit a 50,000-URL site in six working hours instead of two days.
We will walk through the stack, the five prompts, one live audit from Monday crawl to Friday fix, and the three things we still refuse to let Claude close on its own.
The broader workflow this sits inside is covered in our Claude SEO guide. This piece is the technical-audit deep dive.
Screaming Frog Is a Reporting Tool. Claude Is the Analyst.
Screaming Frog crawls, renders, and reports. What it does not do is reason across the report. That is the gap.
Our broader technical SEO for SaaS guide covers the crawler-setup side in depth. Our B2B SEO audit walkthrough frames the full audit motion end to end.
A Screaming Frog export tells you 847 pages have duplicate H1s. It lists every one of them with the exact duplicate text. It does not tell you that 812 of those 847 sit under /integrations/ and share a template pattern "{Product} Integration | Acme."
Claude, reading the same export, surfaces that fact in a single prompt. The actionable finding becomes "fix one template, fix 812 pages in one release" instead of "fix 847 pages one at a time."
That jump, from issue list to pattern finding, is the value.
It also mirrors the way technical SEO leaders like Chris Long at Nectiv have been framing the crawler-plus-LLM pattern on LinkedIn. The crawler collects. The model reasons. The human verifies.
What Our Technical Audits Keep Surfacing
Pattern-level issues account for roughly 65% of the ranking-impacting findings in the B2B SaaS technical audits we run. The individual-page issues make up the other 35%, but most of them resolve when the upstream template pattern is fixed. That is the payoff on running the pattern pass.
The New Audit Economics
Before this pipeline, a 20,000-URL audit ran two working days end to end. Crawl overnight, a full day of spreadsheet filtering, a half-day of prioritization, a half-day of writing up the fix list.
After this pipeline, the same audit runs six working hours. The crawl still runs overnight. The pipeline runs in under an hour. Verification takes an hour or two. Writing the fix list takes another two.
The time savings are not the story. The quality gain is. Pattern-level findings that the spreadsheet filtering pass missed now ship every audit.
The Pipeline: From Crawl Export to Claude Code
We configure Screaming Frog in spider mode with standard SaaS settings. Follow internal links, render JavaScript, respect robots.txt, pull canonicals, H1s, H2s, status codes, response times, structured data.
Google Search Console and Google Analytics 4 integrations run alongside. These are what let Claude cross-reference crawl issues against impression and conversion data in the prompts that follow.
Crawls over 20,000 URLs run overnight.
The export is a folder of CSVs. Internal all, redirect chains, response codes, canonicals, H1 duplicates, structured data, and several more.
The full export set is documented in the Screaming Frog user guide. We leave the default naming so Claude Code can find files by expected names.
We drop the folder into a Claude Code project directory. The filesystem MCP server handles the reads. Claude reasons over the CSVs without copy-paste, without export-import friction, without the spreadsheet.
The Audit CLAUDE.md We Ship With Every Project
Every audit project carries its own CLAUDE.md. It tells Claude what data is where, what the output should look like, and which decisions never belong to it.
The GSC Cross-Reference Is Non-Negotiable
The single biggest reason our audits come back prioritized instead of as a 600-row list of every issue is the GSC cross-reference line in the CLAUDE.md.
An issue on pages with zero impressions is low priority. An issue on pages with 40,000 monthly impressions is high. That distinction should not take a human to make.
We run the same three-layer CLAUDE.md discipline across every engagement. The agency layer is shared, the client layer carries brand context, and the audit task template layers on top.
The Five Prompts That Surface Pattern-Level Findings
Five prompts carry most of the reasoning work. Each one has a narrow job. Chaining them in order produces the prioritized fix list we hand engineering.

Prompt 1. Detect Orphan Pages
We ask Claude to cross-reference the sitemap with the crawl export. Every URL in the sitemap with zero inbound internal links from indexable pages is an orphan.
Claude then scores each orphan by organic traffic in GSC over 90 days. Orphans with zero traffic get deprioritized. Orphans with declining but non-zero traffic move to the top of the fix list.
On B2B SaaS sites over 5,000 pages, we surface 40 to 220 orphans per audit.
The edge cases matter. An orphan that is also noindex is usually a deliberate choice. An orphan that shows up in the XML sitemap but not in GSC's crawled pages is sometimes a crawl budget issue, not a linking one. Claude flags the category. The lead decides.
Prompt 2. Clean Redirect Chain Hygiene
Redirect chains over two hops are the most common finding on SaaS sites that have been through a rebrand or URL migration. Claude reads redirect_chains.csv, flags every chain over two hops, and resolves each to its final destination.
Then a dedup pass. Any URL reached through more than one chain gets flagged for a consolidation decision.
The output is a table engineering can action directly. Original URL, final destination, hop count, current monthly impressions on the original, recommended action.
Prompt 3. Surface Duplicate Patterns
Duplicate H1s and title tags on a typical SaaS site are almost never random. They cluster around a URL pattern: /integrations/{partner}, /industries/{vertical}, /blog/tag/{name}.
Claude clusters the duplicates by URL pattern, not just by text. The output is a short list of five or six URL patterns that contain 80% of the duplicates.
This is where the pattern pass earns its keep. The Screaming Frog report says "847 duplicate H1s." The Claude output says "fix the /integrations/{partner} template, fix 812 pages in one release."
Prompt 4. Flag Crawl Depth Outliers
Claude cross-references crawl depth with GSC impressions. Pages deeper than four clicks from the homepage that still earn impressions are candidates for internal-linking promotion.
Pages shallower than three clicks that earn zero impressions are candidates for consolidation or demotion.
The output feeds directly into our internal linking playbook, where we rebalance the link graph to surface orphaned authority.
The Ahrefs AI SEO statistics compilation backs what we see from a different angle. Brand authority and internal link equity increasingly predict AI citation visibility, not just traditional rankings.
Prompt 5. Map Schema Gaps
Schema coverage is the finding category most often missed in crawler-only audits. Claude reads structured_data.csv and maps which page templates carry valid schema and which do not.
The output is a matrix. Page template on one axis, schema type on the other, coverage percentage in each cell.
It takes the conversation from "we have some schema" to "the /product/ template carries Organization but not Product, and 180 product pages are missing rich-result eligibility."
The fix list then feeds our schema generation workflow where we batch-generate JSON-LD for the flagged templates.
The Crawl Depth Pattern We See Most Often
About 30% of the B2B SaaS site audits we run surface a cluster of high-impression pages sitting at crawl depth five or six. The root cause is almost always a blog that grew faster than the internal linking strategy. Promoting those pages through a site-wide linking refresh is the single highest-ROI action we recommend from most audits.
One Audit, Walked End-to-End
Here is what the pipeline looks like when it runs. A sales enablement SaaS client, 22,000 indexable URLs, and a ranking plateau that had held for six months despite steady content output.
Tuesday Evening: Crawl Kickoff
The technical SEO lead configured the Screaming Frog crawl with GSC and GA4 integration enabled. The crawl ran for seven hours and finished at 3 AM.
No one touched it during the run. That is part of the design.
Wednesday Morning: Pipeline Setup and Run
CSVs moved into the audit project folder at 9 AM. The CLAUDE.md went in with the cross-reference pointers. Total setup: 11 minutes.
The five-prompt chain ran starting 9:15 AM. Orphan detection surfaced 174 orphans. Redirect chain hygiene found 41 chains over two hops. Duplicate pattern surfacing clustered findings around three URL patterns.
Crawl depth flagged 68 high-impression pages sitting at depth five or six. Schema gap mapping showed four of six page templates missing their primary schema type.
Wednesday 10:30 AM: Human Verification
The technical SEO lead spot-checked eight of the surfaced issues against the live URLs. All eight verified.
The lead rejected two of Claude's prioritization calls. Both pages were being sunset at the end of the quarter. Everything else went into the fix list.
Wednesday 11:15 AM: Fix List Delivered
The final output ran 34 rows. Grouped by upstream cause, with severity, page count, recommended action, and estimated effort per row.
The single biggest finding: the /integrations/ template with a duplicate H1 pattern affecting 812 pages. Impact: about 290,000 monthly impressions at risk.
Friday Afternoon: First Fix Shipped
Engineering fixed the /integrations/ template in one release. By day three post-fix, the impression line in GSC had already ticked upward.
Full recovery on that cluster took six weeks. The rest of the fix list landed across the following quarter, tracked through our SEO reporting workflow.
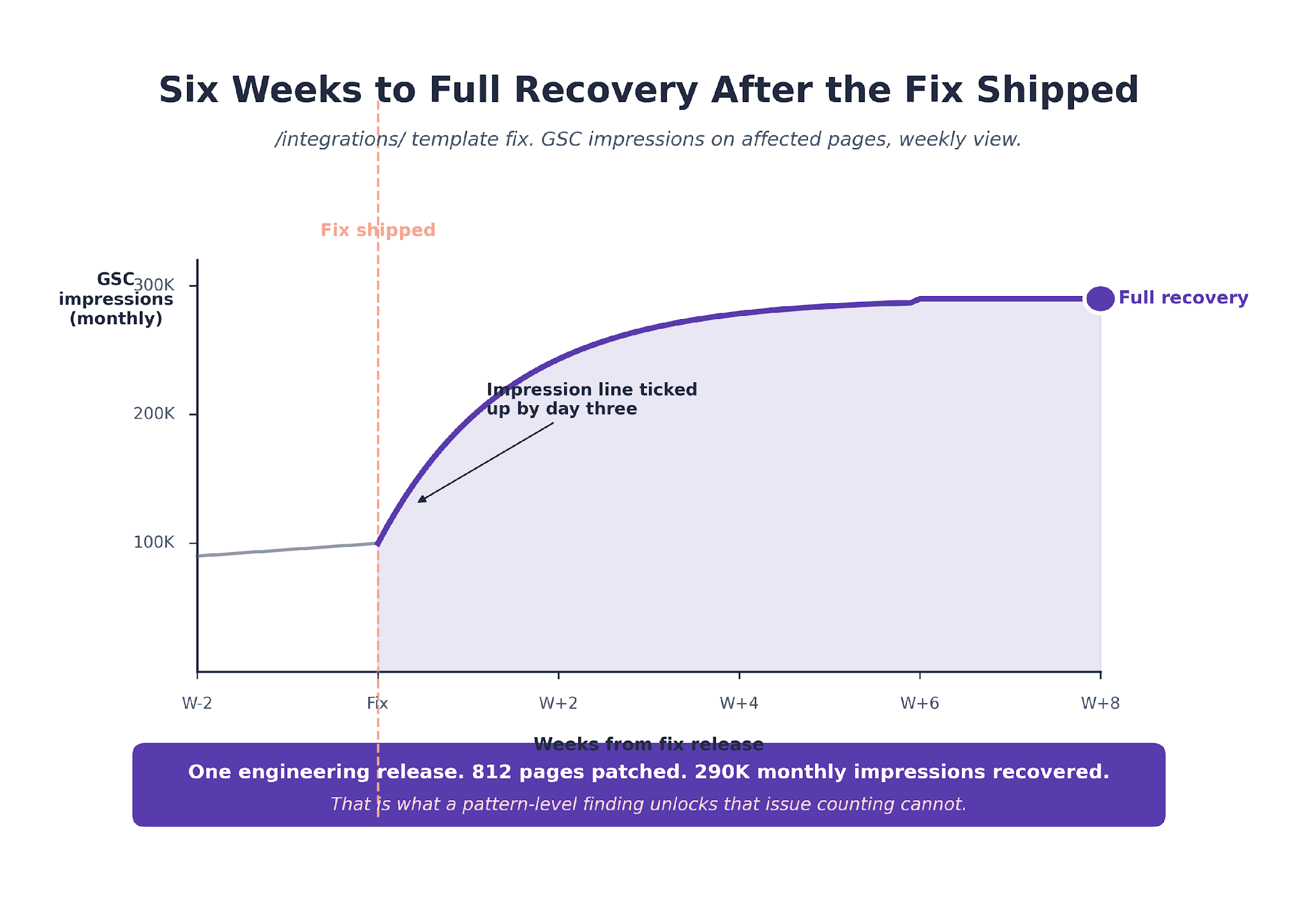
Total audit time end to end: six working hours. The same audit run manually would have taken two working days, and the pattern-level /integrations/ finding would probably have been missed.
What Our Audit Engine Data Shows
About 70 to 80% of the findings Claude surfaces pass human verification unchanged in the audits we run. The remaining 20 to 30% get reshaped by the lead, usually around prioritization or client-specific context Claude could not know. The verification step is short. It is also the difference between a shipped fix list and a speculative one.
What Claude Still Cannot Close Alone
Three checks we keep human-only. Every audit. No exceptions.
Rendered HTML Validation
Claude reads the export Screaming Frog captured at crawl time. It cannot re-render a live page to confirm a fix worked.
The technical SEO lead opens the URL, runs View Source, runs the Rendered DOM inspector, and signs off before anything ships as fixed.
This shows up most on hydrated React or Next.js SaaS sites where the server HTML and the rendered DOM can diverge.
Claude sees only what the crawler captured. A fix that looks correct in the export can be broken in the live DOM. Our SaaS SEO agency engagements keep this step in every audit for exactly that reason.
Canonical Logic on High-Value URLs
Claude can flag bad canonicals. It cannot always tell which canonical is the right one when the same content variant exists across multiple URLs with different marketing purposes.
The call requires knowing the business intent of each URL. Humans make that call.
The canonical rule also protects against one specific failure pattern. Claude occasionally proposes consolidating two URLs that look semantically close but serve different search intents.
An "/alternatives/" page and a "/vs/" page often hit that trap. Both target the same product category. Only one should carry the primary canonical. The decision is a business one, not a data one.
Ranking-Signal Changes on Production
Anything that could change how Google treats a URL is flagged HIGH severity and reviewed by the lead before it ships. Noindex, canonical change, redirect of an indexed URL, hreflang changes.
The cost of a bad change is measured in months of lost ranking. The time saved by skipping review is measured in minutes. Not a trade we take.
The guardrail exists for a specific reason. Early in the pipeline's life, we watched Claude propose a batch canonical change that would have pointed 40 product pages to a single hub.
The logic in the prompt was clean. The outcome in production would have consolidated 40 ranking URLs into one and lost the long-tail traffic across them. The lead caught it. The guardrail has held ever since.

The Search Engine Land write-up on Claude Code as an SEO command center frames the same boundary.
The tool does not collect data. It reasons across data that is already collected. The collection layer and the final sign-off stay where they always have been.
The Verification Gate Pattern
The verification step catches about one finding in every seven that would have been wrong if shipped, across the audits we run. That ratio has held steady for the last year. It is also the main reason we have not tried to remove the step.
Putting This Process Into Practice
Technical audits are the stage where the cost of a bad output is highest and the time savings are cleanest. Getting the pipeline right is less about prompt cleverness and more about the setup.
The service-side framing of this work sits on our technical SEO agency page.
For enterprise-scale sites, our enterprise SEO audit guide covers the chunking approach we default to when the crawl is over 100,000 URLs.
The CLAUDE.md discipline carries most of the weight. The GSC and GA4 cross-reference carries the rest. The verification step is what makes the output shippable.
We run this audit pattern across 250+ B2B SaaS engagements at TripleDart. The pattern carries across WeWork, Atlas, Payoneer, and SignEasy, and across verticals where the only thing in common is a 20,000-plus-URL site with room for pattern-level fixes.
What changes from engagement to engagement is the CLAUDE.md client layer: the brand context, the approved vocabulary, the specific business intent behind canonical and indexation choices. The audit prompts stay the same.
If your team runs monthly Screaming Frog crawls but never reasons across them at pattern level, the audit layer is where you are leaving the most on the table. Talk to our team to see how we would run the first audit on your site.
Frequently Asked Questions
Can Claude replace Screaming Frog?
No. Claude does not crawl, render JavaScript, or build the link graph. It reasons over the data a crawler produces. Every audit we run starts with a Screaming Frog crawl. Claude is the analyst that reads the CSVs.
How long does a typical Claude plus Screaming Frog audit take?
For a 20,000 to 50,000 URL B2B SaaS site, about six to eight working hours end to end. Crawl runs overnight. Claude pipeline runs in under an hour. Human verification takes one to two hours. Writing the fix list takes another two.
What are the most common issues Claude surfaces?
Duplicate H1 patterns on templated page sets, redirect chains over two hops, schema gaps on product and comparison templates, and orphan pages that still earn impressions. The patterns are consistent across the B2B SaaS sites we audit.
Do you use the Screaming Frog MCP or the filesystem MCP?
Filesystem MCP, mostly. Screaming Frog CLI wires into our Claude Code workflows for the crawl itself, but CSV exports are the format Claude reads most reliably. The CLI options sit in the same user guide linked above.
How do you stop Claude from hallucinating a finding?
Two guards, both in the CLAUDE.md. Every finding must cite the exact CSV row ids, so fabricated findings have no supporting row. The technical SEO lead then verifies a sample against the live URLs before any fix goes to engineering. Hallucinations still occur. The guard catches them.
What is the hardest technical SEO issue for Claude to handle?
JavaScript rendering edge cases. If a page renders differently for Googlebot than for a generic crawler, Claude cannot tell from the export. We handle those cases by running a second rendered crawl with a dedicated configuration and verifying manually on the flagged URLs.
Does this workflow scale to enterprise sites?
Yes, with chunking. For sites over 100,000 URLs, we split the crawl export by URL pattern (blog, product, integrations, tag pages) and run the prompt chain per segment. The Claude context window handles individual segments comfortably.
How do the audit findings feed the monthly report
Every audit finding that ships as a fix lands in the next monthly report as a tracked recovery. The /integrations/ fix above landed as the anchor win for that quarter. The reporting workflow we use to track those recoveries is linked in the outcome section above.

.png)




.webp)

















.webp)





.webp)


.webp)
.png)







%20(1).png)



.webp)
.webp)
.webp)





%20Ads%20for%20SaaS%202026_%20Types%2C%20Strategies%20%26%20Best%20Practices%20(1).webp)







.webp)
















.webp)









![Creating an Enterprise SaaS Marketing Strategy [Based on Industry Insights and Trends in 2026]](https://cdn.prod.website-files.com/632b673b055f4310bdb8637d/6a218bacea463474377dfd32_34%20-%20Creating%20an%20Enterprise%20SaaS%20Marketing%20Strategy.png)



















































.webp)














%20Agencies%20for%20B2B%20SaaS%20Compared%20(2026).webp)

.webp)

%20with%20Hubspot.webp)


_%20Expert%20Reviews%20%26%20Comparisons.png)












.webp)

















_%20Comparison%2C%20Strengths%2C%20and%20How%20to%20Choose.png)

















.webp)




.webp)




.webp)













































%20Tools%20in%202026_%20Vetted%20List.webp)





![How to Measure AEO Success: 12 Metrics Beyond Clicks [2026 Framework]](https://cdn.prod.website-files.com/632b673b055f4310bdb8637d/6a0d664b326187e99b3d5960_6%20-%20The%20Ultimate%20Guide%20to%20Measuring%20AEO%20Success%20in%202026.png)
![7-Step Workflow for AEO-Ready Content [2026 Framework]](https://cdn.prod.website-files.com/632b673b055f4310bdb8637d/6a0d55ea88913ede1d3a7123_5%20-%20Workflows%20for%20Optimized%20AEO-Ready%20Content%20Creation.png)
.png)

![How to Structure Content for AEO and GEO [With Templates]](https://cdn.prod.website-files.com/632b673b055f4310bdb8637d/6a0c6a56eb700472e635ff33_1%20-%20How%20to%20Structure%20%20Content%20for%20AEO%20and%20GEO%20%20Summaries%20(2026).png)







.png)
.png)

























.webp)


%20Agencies%20in%202027.webp)
.webp)
![Top 9 AI SEO Content Generators for 2026 [Ranked & Reviewed]](https://cdn.prod.website-files.com/632b673b055f4310bdb8637d/6a2a3e3105bc1a127aae4e8e_34%20-%20Top%209%20AI%20SEO%20Content%20Generators%20for%202026%20%5BRanked%20%26%20Reviewed%5D.webp)






























