Claude Skill for Fact-Checking: Verify Every Stat Before It Gets Published

Key Takeaways
- The three-stage architecture (Claim Extraction, Verification, Synthesis Report) processes a 2,000-word article in under 3 minutes with four AI models working in sequence.
- A typical B2B SaaS blog post contains 8 to 15 verifiable claims. Most teams we audit have a 15% to 25% stale-stat rate across their published archive.
- The production version auto-resolves flagged claims by finding correct data, generating replacement text, and citing the current primary source.
- Fact-checking runs before humanization in the pipeline. This is deliberate: verified language must survive downstream rewrites intact.
- Fintech and cybersecurity verticals have the highest density of date-sensitive claims, making automated fact-checking non-negotiable.
You have probably seen some version of this stat - "73% of B2B buyers prefer self-serve purchasing, according to McKinsey." It shows up in SaaS blog posts everywhere.
The original McKinsey study surveyed 3,500 B2B decision-makers in 2020. The methodology section specifies "self-service channels for reordering existing products," not first-time purchasing decisions. The actual percentage for self-serve in new purchase contexts was 32%.
Three years, one pandemic, and a complete market recalibration later, that number is still being copied verbatim into content published this week.
Not because writers are careless. Because manually verifying every statistic in every draft is a process that does not scale.
This guide shows you how to build a three-stage fact-checking Skill that extracts every verifiable claim from a piece of content, verifies each one against primary sources, and produces a structured report with replacement text for anything flagged. We run this on every piece of content before publication, across every client.
Why Manual Fact-Checking Fails at Scale
Every content team has a version of the same problem. Someone writes a draft. An editor reads it, maybe Googles a stat that looks off, skips the ones that "sound right," and publishes. Nobody checks whether that Gartner prediction was from 2022 or 2024. Nobody verifies whether the sample size behind "87% of marketers" was 50 people or 5,000.
The issue is not negligence. Manual fact-checking a single 2,000-word article properly takes 45 to 60 minutes. That means opening the draft, identifying every verifiable claim, searching for each claim's original source, confirming the claim matches the source, checking the publication date, and noting discrepancies.
At 10 articles per month, that is 10 hours of pure verification work. At 40 articles per month, it is a full-time job that nobody has.
So teams do what every team does: spot-check. Verify the stats that look suspicious. Trust the rest. And accumulate a steadily growing pile of outdated, misattributed, and occasionally incorrect claims across their content library.
For content marketing teams publishing at scale, this creates a compounding credibility problem. One stale stat is ignorable. Twenty across your blog archive erodes trust with exactly the readers who matter most: the ones who check sources before they book a demo.
For the foundational concepts behind Claude Skills and the DBS framework, start with our complete guide.
The Three-Stage Architecture
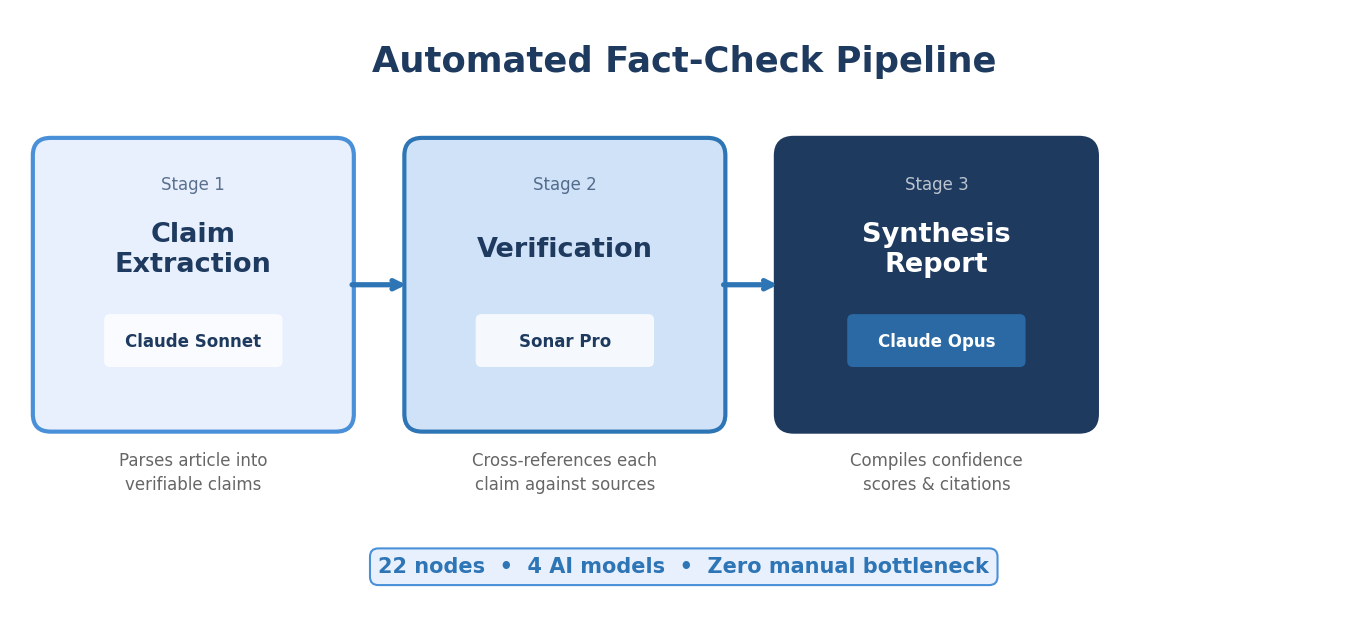
TripleDart’s pipeline runs 22 nodes across 4 AI models with zero manual bottleneck between stages. Here is what each stage does, with a concrete example running through all three.
Our example article: a 1,800-word blog post about B2B SaaS purchasing trends. It contains 11 verifiable claims.
Stage 1: Claim Extraction (Claude Sonnet)
Claude Sonnet reads the full article and extracts every verifiable factual claim as a numbered list. The extraction is comprehensive. It catches claims that human reviewers routinely miss: percentages embedded in compound sentences, implied comparisons, date-specific assertions buried in supporting paragraphs, and attributed quotes with specific figures.
Direction Prompt for Stage 1:
You are a fact-checking analyst for B2B SaaS marketing content.
TASK: Read the content below and extract every verifiable factual
claim as a numbered list.
A VERIFIABLE CLAIM includes:
- Percentages or numerical statistics (e.g., "73% of buyers...")
- Named research studies or reports (e.g., "according to Gartner...")
- Company-specific data points (funding rounds, headcount, revenue,
capabilities)
- Date-specific assertions (e.g., "launched in Q3 2025")
- Regulatory or compliance statements (e.g., "SOC 2 Type II
requires...")
- Market size or growth figures (e.g., "$4.2B market by 2027")
- Rankings or comparison claims (e.g., "the fastest-growing
category in SaaS")
EXCLUDE:
- Opinions and subjective assessments
- General best practices without specific attribution
- Hypothetical scenarios and examples
- Author's original analysis or recommendations
OUTPUT FORMAT (per claim):
Claim #[N]
- Text: [exact quote from the content]
- Type: [Statistic | Study | Company Data | Date Claim |
Regulatory | Market Data | Ranking]
- Source cited in content: [source name if mentioned, or "None"]
- Location: [paragraph number or section heading]
- Priority: [HIGH if the claim is central to the article's
argument, MEDIUM if supporting, LOW if tangential]
What the extraction output looks like for our example article:
Claim #1
- Text: "73% of B2B buyers prefer self-serve purchasing,
according to McKinsey"
- Type: Statistic
- Source cited: McKinsey
- Location: Introduction, paragraph 2
- Priority: HIGH
Claim #2
- Text: "The B2B e-commerce market reached $20.9 trillion
in 2024"
- Type: Market Data
- Source cited: None
- Location: Section 2, paragraph 1
- Priority: MEDIUM
Claim #3
- Text: "Gartner predicts 80% of B2B sales interactions
will occur in digital channels by 2025"
- Type: Study
- Source cited: Gartner
- Location: Section 2, paragraph 3
- Priority: HIGH
Claim #4
- Text: "Companies with self-serve purchasing options see
2.3x faster deal velocity"
- Type: Statistic
- Source cited: None
- Location: Section 3, paragraph 1
- Priority: MEDIUM
[...continues through Claim #11]
Notice what the extraction catches that a human editor might skip. Claim #4 has no source attribution at all. Claim #2 cites a specific dollar figure without naming where it came from. Claim #3 references a Gartner prediction with a target year that has already passed. Each of these requires verification, and each would likely survive a manual editorial pass because they "sound right."
Stage 2: Verification (Sonar Pro Web Search)
Each extracted claim gets an individual verification search through Sonar Pro with web search enabled. The critical instruction: find the ORIGINAL primary source, not a secondary article citing the same statistic.
Direction Prompt for Stage 2:
You are a research verification specialist. For each claim
below, perform a web search to find the ORIGINAL PRIMARY SOURCE.
VERIFICATION RULES:
- A primary source is the organization that conducted the
research or published the data. Blog posts and news articles
citing the data are NOT primary sources.
- Check whether the primary source supports the claim AS STATED
in the content. Partial matches, misquotations, and rounded
figures should be flagged.
- Check the publication date. Data older than 3 years from the
current date (April 2026) should be flagged as potentially
outdated.
- When the original source is behind a paywall, note this and
search for the publicly available summary, press release,
or abstract.
VERIFICATION STATUS:
- VERIFIED: Primary source found, claim matches, data is current
- OUTDATED: Primary source found, claim was accurate when
published, but data is now older than 3 years
- INCORRECT: Primary source found, claim does not match (wrong
percentage, wrong attribution, misquoted context)
- UNVERIFIABLE: No primary source found after thorough search
OUTPUT FORMAT (per claim):
Claim #[N]: [original claim text]
Status: [VERIFIED | OUTDATED | INCORRECT | UNVERIFIABLE]
Primary Source: [URL and publication name]
Publication Date: [date]
What the source actually says: [exact quote or summary]
Discrepancy (if any): [specific difference between claim and source]
Replacement suggestion: [corrected text if status is INCORRECT
or OUTDATED, with current source]
What the verification results look like:
This is where the Skill earns its keep. Claim #1 is the most dangerous type of error: a real statistic from a real source, cited in a way that changes its meaning. A human editor would Google "73% B2B buyers self-serve McKinsey," find multiple secondary sources repeating the claim, and mark it as verified. The Skill traces it back to the original report and catches the context mismatch.
Stage 3: Synthesis Report (Claude Opus with Extended Thinking)
The final stage takes all verification results and produces a structured report for the content editor. Claude Opus handles this stage because synthesis across multiple sources with nuanced uncertainty language requires the strongest reasoning model available.
Direction Prompt for Stage 3:
You are a senior editorial fact-checker producing a final
verification report.
INPUT: You will receive the original content and verification
results for each extracted claim.
TASK: Produce a structured fact-check report AND a corrected
version of the full content.
REPORT STRUCTURE:
1. EXECUTIVE SUMMARY
- Total claims checked: [N]
- Verified: [N] | Outdated: [N] | Incorrect: [N] |
Unverifiable: [N]
- Content Reliability Score: HIGH (0-1 issues) /
MEDIUM (2-3 issues) / LOW (4+ issues)
- Critical issues requiring immediate attention: [list]
2. HIGH PRIORITY ISSUES (Incorrect + Outdated)
For each:
- Original text (exact quote with location)
- What is wrong (specific discrepancy)
- Corrected replacement text with accurate source citation
- Source URL
3. MEDIUM PRIORITY ISSUES (Unverifiable)
For each:
- Original text
- Why it cannot be verified
- Recommended action: REMOVE / REPLACE / QUALIFY
- If REPLACE: suggested alternative with verifiable source
4. VERIFIED CLAIMS (for the record)
- Brief confirmation per claim
5. CORRECTED CONTENT
- Full article text with all corrections applied
- New/changed text marked in **bold**
- Source citations added in [brackets]
TONE: Direct, specific, and actionable. The editor reading
this report should be able to make every correction in under
10 minutes.
What the synthesis report excerpt looks like:
EXECUTIVE SUMMARY
Total claims checked: 11
Verified: 6 | Outdated: 3 | Incorrect: 1 | Unverifiable: 1
Content Reliability Score: LOW (5 issues flagged)
Critical issues: Claims #1, #4 require immediate correction
before publication.
HIGH PRIORITY ISSUES
Issue 1 (Claim #1), INCORRECT
Location: Introduction, paragraph 2
Original: "73% of B2B buyers prefer self-serve purchasing,
according to McKinsey"
Problem: The McKinsey study (Feb 2022) found 73% preference
for self-service REORDERING of existing products.
Self-serve preference for new purchases was 32%. The claim
as written conflates reordering with all purchasing.
Correction: "73% of B2B buyers prefer self-service channels
for reordering existing products, according to McKinsey's
2022 B2B growth equation report. For first-time purchases,
that preference drops to 32%."
Source: https://www.mckinsey.com/capabilities/growth-marketing
-and-sales/our-insights/the-new-b2b-growth-equation
Issue 2 (Claim #4), UNVERIFIABLE
Location: Section 3, paragraph 1
Original: "Companies with self-serve purchasing options see
2.3x faster deal velocity"
Problem: No primary source found. Multiple secondary sources
cite this figure but none link to original research. Likely
originated from a vendor marketing claim that propagated
without attribution.
Recommended Action: REPLACE
Replacement: "Companies implementing digital self-service
purchasing report 20-30% reduction in sales cycle length,
according to Forrester's 2025 B2B Buyer Experience Survey."
Source: [Forrester URL]
The corrected content section delivers the full article with every fix applied, new text bolded, and source citations embedded. An editor opens the report, scans the executive summary, reviews the corrections, and approves. Total editorial time: 5 to 10 minutes instead of 45 to 60.
The Production Pipeline Order
The Fact-Check Skill sits at a specific point in the content production pipeline. The sequence matters, and getting it wrong undermines the entire system.
The correct order:
- Draft creation (human or AI-assisted)
- Fact-Check every claim, auto-resolve errors
- Humanize to remove AI writing patterns
- Internal Linking via the internal linking Skill
- External Linking to add source citations
- Editorial Review (human final pass)
- Publish
Why does fact-checking come before humanization? Two reasons.
First, the humanizer rewrites sentences. If a claim says "73% of B2B buyers prefer self-serve purchasing" and the humanizer rephrases it to "nearly three-quarters of B2B buyers want to buy without talking to sales," you have now lost the precise language that was verified. Running fact-check first ensures the verified numbers and attributions are locked in before any stylistic rewriting happens.
Second, the humanizer may introduce imprecision. Rounding "73%" to "nearly three-quarters" is fine if the original claim was verified. But if the original claim was incorrect and should have said "32%," the humanizer would be polishing a wrong number. Verify first, then polish.
This pipeline order is consistent across all content types. Content briefs feed into drafts, drafts feed into fact-checking, and fact-checked output flows through humanization and linking before editorial review. For GEO-optimized content, fact-checking is especially critical because AI search platforms prioritize accurately sourced content in their citations.
Source Priority by Vertical
Not all sources are equal, and different verticals have different authority hierarchies. The Direction prompt for Stage 2 includes a source priority tier that varies by client vertical.
Fintech Source Priority
For fintech content, the Skill prioritizes sources in this order:
- Regulatory bodies: SEC, CFPB, OCC, FCA, MAS filings and press releases
- Central bank publications: Federal Reserve, ECB, Bank of England research papers
- Analyst firms: McKinsey Financial Services, Deloitte, EY reports
- Industry research: CB Insights fintech reports, PitchBook data
- Trade publications: American Banker, The Banker, Finextra
A fintech article claiming "Open banking adoption in the EU reached 11.4 million users" should trace to an EBA or PSD2 implementation report, not a TechCrunch summary. The Skill's verification search prioritizes regulatory body publications first and flags secondary citations as insufficient.
Cybersecurity Source Priority
For cybersecurity content, source priority shifts:
- Government agencies: CISA, NIST, ENISA advisories and frameworks
- Threat intelligence: CrowdStrike, Mandiant, Recorded Future annual reports
- Industry research: Ponemon Institute, SANS Institute, Verizon DBIR
- Analyst firms: Gartner Magic Quadrant, Forrester Wave reports
- Vendor-neutral publications: Dark Reading, CSO Online, Krebs on Security
A cybersecurity article citing "the average cost of a data breach reached $4.88 million in 2024" should verify against the IBM/Ponemon Cost of a Data Breach Report directly, not against a blog post quoting the same number. The Skill checks for the specific report edition, sample size, and geographic scope to ensure the claim matches the article's context.
How to Build Your Own Starting with Three Calls
You do not need a 22-node pipeline to start. The three-stage framework works as three sequential API calls with Sonar Pro handling the verification search.
Call 1: Claim Extraction. Send your article to Claude Sonnet with the Stage 1 Direction prompt above. You get back a numbered claim list.
Call 2: Verification. For each extracted claim, send a verification query to Sonar Pro (or any model with web search). The query format: "Find the original primary source for: [claim text]. Verify accuracy and check publication date."
Call 3: Synthesis. Send the original article plus all verification results to Claude Opus with the Stage 3 Direction prompt. You get back the structured report and corrected content.
Total API cost per article: under $0.50. Total processing time: 2 to 3 minutes.
Start by running this on your last 10 published articles as a baseline audit. Most B2B SaaS blogs we have audited run 15% to 25% of statistics as outdated or unverifiable. That percentage is your business case for making fact-checking a pipeline standard rather than an occasional spot-check.
Once the three-call version is working reliably, you can evolve it. Add batch processing to run against your full archive. Add the auto-resolution layer where the Skill finds correct data and generates replacement text instead of only flagging issues. Add vertical-specific source priority lists. Add quarterly re-verification of previously checked claims, because a claim that was current six months ago may not be current today.
For teams building a broader Skill stack, the fact-checker pairs naturally with the content brief Skill. Briefs that include source requirements and mandatory primary citations reduce the volume of issues the fact-checker catches downstream. Prevention and verification work together.
The keyword research Skill also connects here. High-intent keywords in regulated verticals like fintech and cybersecurity need content that passes the highest source verification bar. Identifying those terms early means flagging which drafts need the strictest fact-checking pass.
What Happens When You Run This Across an Archive
We ran the fact-checking Skill across a 120-post SaaS blog archive for a client in the HR technology space. The results:
- Total claims extracted: 1,247
- Verified: 812 (65.1%)
- Outdated: 268 (21.5%)
- Incorrect: 47 (3.8%)
- Unverifiable: 120 (9.6%)
One in five statistics was outdated. Nearly one in ten had no traceable primary source. And 47 claims, roughly one every three articles, were provably incorrect.
The incorrect claims were not obvious errors. They were the subtle kind: a Gartner prediction cited after its target year passed, a survey percentage applied to a broader population than the study surveyed, a market size figure from 2021 used in a 2024 article without noting the date.
These are the claims that survive editorial review because they "sound right." They are also the claims that a fintech compliance officer or a CISO evaluating vendors will catch in about 15 seconds.
The client prioritized corrections by traffic. The 20 highest-traffic posts got corrected within two weeks. The rest followed over the next month. Their SEO content strategy now includes fact-checking as a standard pipeline step on every new piece.
TripleDart runs fact-checking on every content piece across every client before publication. The three-stage pipeline catches the claims that human editors miss, and the auto-resolution layer generates corrected text so your editor spends 5 minutes reviewing instead of 45 minutes researching.
Book a meeting with TripleDart to see the verification report format and discuss deployment for your content pipeline.
Try Slate here: slatehq.com
Frequently Asked Questions
How accurate is automated fact-checking compared to a human reviewer?
For searchable claims (statistics, studies, company data, market figures), the Skill is more thorough and more consistent. It checks every claim systematically while human reviewers tend to spot-check the claims that look suspicious and trust the rest. Where humans still add value: evaluating whether a technically accurate claim is contextually misleading. The Opus synthesis stage flags these, but a human editor makes the final call.
What happens when the Skill cannot find a primary source?
The claim gets flagged as Unverifiable with a recommended action: remove the claim entirely, replace it with a verifiable alternative (the Skill suggests one), or add a qualification phrase like "industry estimates suggest" to signal that the figure lacks a confirmed primary source.
Can I run the fact-checker on competitor content?
Yes. Identifying where competitors publish outdated or incorrect statistics creates opportunities to publish better-sourced content on the same topics. If a competitor's top-ranking article cites a 2021 market size figure, publishing an updated piece with 2025 data and a primary source citation is a straightforward content angle.
Should fact-checking run before or after humanization?
Before. Always before. Fact-check the original draft so verified language is locked in, then humanize the verified version. Running it the other direction means the humanizer may rephrase claims in ways that obscure the original verified wording.
How does the Skill handle paywalled sources?
It flags paywalled content as "Source not publicly accessible" and searches for equivalent data from publicly available primary sources: press releases, report summaries, executive briefings, or academic paper abstracts. If no public equivalent exists, the claim gets flagged for manual verification by the editorial team.
What is the cost per fact-check run?
Under $0.50 per article for API costs. The multi-model pipeline is efficient because extraction and verification search use lighter models (Sonnet and Sonar Pro). Only the synthesis stage uses Opus. A 120-article archive audit costs approximately $50 to $60 in API fees.
How does the Skill handle claims that are technically accurate but contextually misleading?
The Opus synthesis stage catches these. A claim like "AI adoption grew 300%" might be technically accurate over a five-year period but misleading if presented as a recent trend. The Skill flags it with a context recommendation: add a date range qualifier, specify the baseline, or replace with a more precisely framed statistic.
How often should published content be re-verified?
Quarterly for high-traffic pages. Annually for the rest of the archive. Statistics that were current at publication become outdated as new research publishes. We run quarterly re-verification audits across all client content libraries, prioritized by organic traffic. This matters most for fintech and cybersecurity content where regulatory data, threat statistics, and market figures change rapidly.

summarize with ai




