The Long-Tail Keyword Strategy That Holds Up in 2026

Key Takeaways
- The old long-tail playbook stopped working once AI Overviews started intercepting 30 to 60 percent of click-through on long-tail informational pages.
- Citation eligibility, not search volume, is the right unit of analysis in 2026. A page lifted by Perplexity, ChatGPT, or Google AIO contributes brand pull a high-volume ranking page can no longer guarantee.
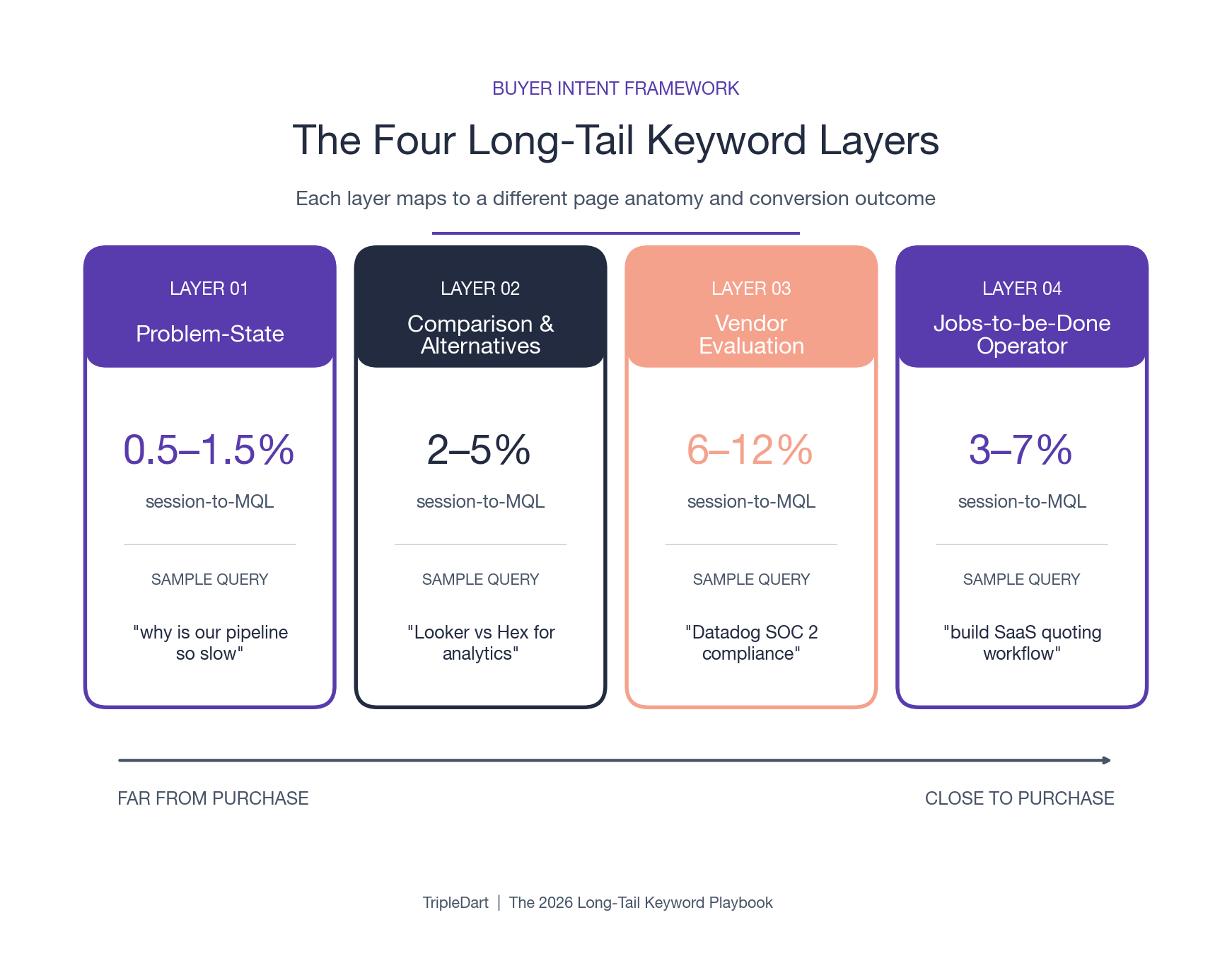
- The four-layer model splits long-tail by buyer state: problem-state, comparison and alternatives, vendor-evaluation, and jobs-to-be-done. Each layer carries a different page anatomy and a different conversion outcome.
- Discovery quality is set by source order. Sales call notes, support tickets, and win-loss interviews surface the highest-conversion queries. Keyword tools belong third in the order, not first.
- The teams that scale long-tail run a quarterly workflow with AI citation tracking layered on top of ranking measurement, plus a Search Console cannibalization check every Monday.
- Budget math for a 40-page cluster runs $48,000 to $72,000 in year one, including writing, design, schema engineering, and citation tracking. The payback window opens in months 9 to 14.
Why Long-Tail Keyword Strategies Fail in 2026
Long-tail used to be a traffic bet. In 2026, it is a citation bet.
Pages that ranked for low-volume queries from 2018 to 2022 captured close to the full click-through their position suggested. The same pages now lose between 30 and 60 percent of that click-through to AI summaries that lift the answer and never send the visitor.
We see this pattern across the SaaS SEO landscape when we audit incoming sites. The same long-tail informational page that competitors produced 800 monthly sessions from in 2022 now produces 300 to 500 across most SaaS categories.
The gap is absorbed by Google AI Overviews and ChatGPT answers that quote the page directly. The page is still doing the work. The traffic is no longer the proof.
The old playbook assumed three things that broke between mid-2024 and late-2025:
1. Google was the only judge of the page: Buyers now sweep ChatGPT and Perplexity before they ever see a Google SERP. Those engines apply different criteria to pick which page to lift: direct-answer openers, named entities, structured data, recency signals, citation hygiene.
2. Informational queries fed bottom-funnel pages through email nurture: AI engines intercept the informational query, answer it on their surface, and never pass the visitor through to the gated nurture flow. The TOFU-to-MOFU bridge collapsed.
3. Ranking position equaled traffic in a stable ratio: A #1 ranking with an AI Overview above it now produces 40 to 60 percent of the click-through a #1 ranking in 2022 produced. The ratio is no longer stable.
What the Citation Data Keeps Showing
Across the SaaS sites we audit, the long-tail pages losing the most traffic to AI Overviews are also the ones with the highest citation lift. The page that lost 45 percent of its click-through in Q3 2025 is often the same page being lifted into 12 to 20 Perplexity answers a week. Citation visibility moved up the funnel; click visibility moved down.
The rest of this guide rebuilds the long-tail strategy from the unit of analysis up.
It walks the four-layer conversion model, the page templates we ship for each layer, the discovery prompts and interview scripts, the KPI dashboard, the cannibalization detection workflow, the budget math, and the 12-week launch sequence.

What Makes a Page Citation-Eligible for AI Search
Citation eligibility is the page's ability to be the answer an AI engine lifts, with the brand attribution intact. It is the 2026 successor to ranking position.
Volume tells you who could see the page. Citation eligibility tells you who will read your answer back to your buyer through ChatGPT, Perplexity, or Google AI Overviews.
A page becomes citation-eligible through structural and semantic signals that AI engines weigh heavily:
- Direct-answer openers: Each section's opener answers the section's implicit question in one self-contained sentence, 30 to 60 words. AI engines lift these openers verbatim, so they have to read as standalone answers.
- Explicit named entities: Companies, tools, frameworks, and concepts are named on first mention, not referenced through pronouns or inference. "Datadog Synthetic Monitoring" beats "their synthetic offering" by a wide margin in citation tests.
- Inline definitions on first use: A term that an AI engine might want to lift gets defined in 8 to 15 words in the same sentence. "Paid-attributable CAC, which isolates the cost of customers who first touched through a paid channel, runs 1.4x to 1.8x the blended figure."
- Structured data: FAQ schema on the FAQ block. Article schema with the author entity. BreadcrumbList schema. Comparison tables as HTML tables with header rows, not images.
- Primary source citations: Links to original research (Sparktoro studies, position.digital reports, Backlinko keyword data) rather than other summary pages. AI engines weight source proximity heavily.
- Stable URL with a recent update date: Pages with dateModified schema in the last 90 days get cited at higher rates than equivalent pages without the freshness signal.
The operational consequence: a long-tail bet stops being measured by where it ranks. It gets measured by whether AI engines lift it. The downstream decisions all change.
Our GEO and AEO programs operate on this principle. When a B2B SaaS site comes to us with a long-tail portfolio that has stopped producing pipeline, the first audit pass is rarely about ranking.
It is about which pages are still being seen at all in the answer surfaces buyers now use. The B2B SaaS AEO guide walks through the structural pass we run on each candidate page.
The reframe is the work. Once a SaaS team agrees that citation eligibility is the criterion, the page templates and the discovery order downstream of it all change shape.
How to Classify Long-Tail Keywords by Buyer Intent
Long-tail queries split cleanly into four layers when sorted by buyer state. Each layer carries a different conversion timeline, a different SERP density, and a different page anatomy.
Building a page for the wrong layer is how teams end up with traffic that does not convert and conversion gaps that never close. The four layers, in order of distance from the buyer's purchase decision:
Layer 1: Problem-State Queries
A problem-state query is what a buyer types when they know they have a problem but have no vendor in mind. Examples: "why is revenue recognition for usage-based pricing so messy" or "how to forecast SaaS churn without a data team."
These rarely convert on first visit because the buyer is two or three sessions away from being shortlist-ready.
Their job inside a SaaS content portfolio is brand reach. Be the cited answer when the buyer asks an AI engine the same question. Branded search rises four to eight weeks later when the buyer comes back to look the brand up directly.
A SaaS team that abandons Layer 1 because the conversion rate is low loses its AI visibility. That move starves the next two layers of branded entry points.
Layer 1 page anatomy (the template we ship):
- H1 mirroring the query verbatim where possible.
- Sub-headline that previews the answer in 12 to 18 words.
- Direct-answer paragraph (one sentence, 30 to 60 words) immediately under the H1.
- Five to seven body H2s, each opening with a direct-answer sentence.
- One comparison table or numbered list per page (high-lift formats for AI engines).
- One primary-source citation per H2, inline with the claim.
- FAQ block at the bottom (six to eight questions, all in H3 with FAQ schema).
- Article schema with author, dateModified, publisher, and sameAs linking the brand entity to its Wikipedia, Crunchbase, and Linkedin URLs.
- Word count 1,800 to 2,400. Longer is rarely better at this layer.
Layer 2: Comparison and Alternative Queries
A comparison or alternative query is what a buyer types when they are solution-aware and shortlisting. Examples: "Looker vs Hex for analytics teams" or "Notion alternatives for engineering documentation."
Conversion rates here run an order of magnitude higher than Layer 1. Volume is thinner. SERPs are dense with competitor blogs.
Citation eligibility matters heavily, since AI engines lift comparison tables wholesale into their answers. A well-built Layer 2 page typically produces 2x to 5x the session-to-MQL rate of a Layer 1 page in the same portfolio.
Layer 2 page anatomy:
- H1 that names both vendors or names the category + "alternatives".
- One paragraph framing the decision (who the buyer is, what they are weighing).
- A primary comparison table with 8 to 14 rows: pricing, deployment model, ICP fit, support tier, integrations count, security posture, contract terms, AI features, data residency, free tier availability.
- A second table for vendor-specific strengths (4 to 6 rows each).
- A "best for" verdict section (3 to 5 buyer scenarios, each mapped to a recommendation).
- FAQ block addressing the 6 to 8 most-asked side-by-side questions.
- Word count 2,400 to 3,200.
The single most-lifted element by AI engines on Layer 2 pages is the comparison table. Get the row labels right and the page earns citations even on weeks when its ranking drops.
Layer 3: Vendor-Evaluation Queries
A vendor-evaluation query is what a buyer types when they are already on a shortlist. Examples: "Datadog SOC 2 compliance," "Pendo pricing for Series B startups," or "does Segment support EU data residency."
These pages carry the highest pipeline-to-traffic ratio in any SaaS content portfolio.
A pricing page or compliance documentation page typically produces 6 to 12 percent session-to-MQL rates in our SaaS SEO portfolios, against blog content that produces 0.5 to 1.5 percent.
The volume is thin. The buyer who arrives is already most of the way to a decision.
Layer 3 sub-templates by page type:
- Pricing page: Plan tier table with monthly and annual pricing, feature inclusion per tier, seat caps, usage limits, contract terms, customer logos per tier, FAQ on price changes, ROI calculator embed.
- Security page: Certifications visible above the fold (SOC 2 Type II, ISO 27001, HIPAA, PCI DSS as relevant). Architecture diagram. Encryption at rest and in transit specifics. Pen test cadence. Incident response RTO/RPO. Customer-facing audit report download (gated for shortlist credibility).
- Compliance page: GDPR, CCPA, HIPAA, FedRAMP per buyer region. Data Processing Agreement download. Sub-processor list with location. Data retention policy. Customer rights workflow.
- Integration page: Native integration list with logos, with the top 5 broken out individually with screenshots and setup time. iPaaS support (Workato, Tray, Zapier).
- Data residency page: Region map with deployment options. Per-region certifications. Latency benchmarks per region. Customer choice mechanism.
Layer 4: Jobs-to-Be-Done Operator Queries
A jobs-to-be-done query is what a practitioner types when they are trying to execute a specific task. Examples: "how to build a SaaS quoting workflow without engineering" or "best way to track product activation in a freemium app."
Layer 4 pages tend to produce the fastest pipeline curve because the SERP is less defended.
The operator who reads them often has buyer authority. They convert through demo bookings because the page answers the operator's question in a way that demonstrates product fit without selling it.
Layer 4 page anatomy:
- H1 that mirrors the operator question.
- Direct-answer paragraph naming the approach in one sentence.
- Five to seven numbered steps, each as an H3.
- Per step: what to do, what tool or feature handles it, what success looks like, what to watch out for.
- Embedded product screenshot or short video clip per step (showing how the product makes the step easier).
- A "what you skipped if you tried this without a product" section near the end.
- FAQ block addressing implementation edge cases.
- Word count 2,200 to 3,000.
The product integration in Layer 4 pages is the part most SaaS teams underplay. The page is not a sales pitch. It is a working how-to that happens to demonstrate where the product saves time. A page that wins Layer 4 rankings without product integration converts at half the rate.
How Long-Tail Keyword Clusters Drive SaaS Pipeline
A long-tail cluster pays off through rollup math that head-term bets cannot match in 2026.
Forty pages each ranking for six to eight low-volume queries with 30 to 80 monthly searches produce 8,000 to 12,000 monthly sessions across the cluster.
Of those sessions, 2 to 4 percent convert when the cluster is weighted toward Layer 3 and Layer 4 pages.
The same outcome from a single head-term win would require ranking #1 against domains 30 to 50 DR points above the SaaS site. Most B2B SaaS teams cannot achieve that inside an 18-month window.
Worked example: a billing-SaaS cluster.
Consider a B2B billing platform building a 40-page cluster around usage-based pricing operations. The cluster splits:
- 8 Layer 1 problem-state pages ("why is usage-based revenue recognition so messy", "what counts as a meter event in SaaS billing", etc.)
- 12 Layer 2 comparison and alternatives pages ("Stripe Billing vs Chargebee for usage", "Metronome alternatives for finance teams", etc.)
- 12 Layer 3 vendor-evaluation pages (pricing tier, security posture, ERP integrations, regional residency, audit logs, etc.)
- 8 Layer 4 jobs-to-be-done operator pages ("how to set up tiered metering", "best way to handle proration on plan changes", etc.)
At month 12, the cluster typically produces:
- 9,000 to 11,000 monthly organic sessions across the 40 pages.
- 280 to 440 monthly MQLs at a blended 3.2 to 4.0 percent session-to-MQL rate (weighted by the Layer 3/4 weighting).
- 18 to 32 monthly demo bookings at the typical SaaS MQL-to-demo rate.
- Branded search lift of 35 to 60 percent over the pre-cluster baseline (attributable to Layer 1 citation visibility).
AI engines treat well-built clusters as topical authority signals. A 40-page cluster on usage-based billing gets lifted into Perplexity answers about usage-based billing even on the individual pages with low search volume.
The lift happens because the cluster as a whole positions the SaaS site as an authority entity. That authority signal increasingly decides which brands an AI engine cites when a buyer asks a category question.
Inside the Aggregate Cluster Curves We See
Across the SaaS portfolios we have grown past 200 monthly organic leads, the clusters that produced the most pipeline carried a 60-30-10 weight: 60 percent Layer 3 and 4 pages, 30 percent Layer 2 pages, 10 percent Layer 1 pages. Programs that inverted the weight (60 percent Layer 1) typically plateaued at half the lead volume by month 12.
The cannibalisation risk. Two pages targeting the same buyer state with overlapping keyword sets compete with each other rather than with the SERP.
We see this most often in clusters built without an intent classification at the start. A team writes a Layer 3 pricing page, then six months later writes a Layer 4 operator page that drifts into pricing territory.
Both pages lose ranking to a competitor that built one consolidated page covering the same ground.
The detection workflow we run every Monday:
- Pull the Search Console query report for the cluster (last 28 days).
- For every query with more than 50 impressions, list the top 3 ranking URLs from the site.
- Flag any query where two cluster URLs appear in the top 3. That is a cannibalization candidate.
- For each flagged query, decide: merge the two pages, narrow one page's intent, or kill the weaker one.
Our SaaS content strategy framework opens with a cluster intent map before any page gets briefed, specifically to avoid the cannibalisation pattern.
How to Find Long-Tail Keywords for SaaS in 2026
The teams that scale long-tail run discovery in a specific order. The order counts more than the tool list.
Discovery quality is set by where the queries come from, not how many tools you use to validate them. The order we run for SaaS clients:
1. Sales call notes and recorded discovery calls: Operators in the buyer seat use language that buyer-intent tools do not surface. The queries that pull from sales calls are typically the highest converting in the portfolio.
2. Support tickets and customer success interviews: Existing customers describe their problem in the exact phrasing other buyers in the same category will use. Support ticket subject lines and CS call notes are dense with Layer 1 and Layer 4 queries that no tool surfaces.
3. Win-loss interview transcripts: Buyers who chose you and buyers who chose a competitor both describe the decision in the language of their problem. Win-loss transcripts often surface the Layer 2 comparison queries that count most.
4. AI-engine prompting: Ask ChatGPT and Perplexity what people in your category typically search around a problem, then validate against search volume tools. AI engines surface different long-tail patterns than tools like Ahrefs because they aggregate across forums, support sites, and review platforms.
5. Community mining: Niche subreddits, category-specific Slack groups, Indie Hackers, and review-site Q&A pages contain queries phrased by operators rather than marketers. The phrasing is closer to how buyers type into AI engines.
6. Google Search Console data: Your own search-query report surfaces long-tail terms you already rank for but have not built dedicated pages around. Fastest wins because the topical authority is partially in place.
7. Keyword tools: Ahrefs, Semrush, AlsoAsked, AnswerThePublic, and Google Autocomplete validate volume and surface variations. They belong at this stage, not earlier.
The discovery prompts we use with ChatGPT and Perplexity.
For Layer 1 problem-state discovery:
You are a senior product marketing manager at a [category] SaaS company. List the 30 most-typed Google and ChatGPT queries from buyers who have a problem in [specific operational area] but have not yet picked a vendor. For each query, tell me: (a) the phrasing as a buyer would type it, (b) the underlying job-to-be-done, (c) what answer they are hoping for. Group queries by the underlying job.
For Layer 2 comparison discovery:
List the 25 most-searched comparison queries between [our vendor] anddirect competitors in the [category] space. For each, give me the exactSERP phrasing buyers use ("X vs Y", "X compared to Y", "alternatives to X","X or Y for [use case]"). Include alternatives-to queries even when thenamed alternative is a category leader rather than a direct competitor.
For Layer 4 JTBD discovery:
You are a [practitioner role: RevOps lead / Finance ops / DevOps engineer]at a Series B SaaS company. List the 25 most-searched "how to" and"best way to" queries you would type when trying to execute [specific task]without resorting to a custom engineering build. For each, give me theexact query, the underlying success criterion, and what tools you wouldexpect to be evaluated against.
The sales/CS interview script. When we sit with a client's sales team to harvest Layer 3 and Layer 4 queries, the questions we ask:
- What is the exact phrasing prospects use in the first 5 minutes of a demo to describe their problem?
- What is the question buyers ask most often about pricing that is not on our public pricing page?
- What is the security or compliance question that comes up in 80 percent of enterprise deals?
- What is the integration that prospects ask about that we do not currently document?
- What is the operator question we hear most in technical evaluation calls?
- What objection do we hear from buyers who chose a competitor?
Each question produces 3 to 7 long-tail query candidates. A 90-minute session with a sales team typically harvests 40 to 80 candidate queries.
Tools alone produce a keyword list that looks great in a spreadsheet and converts at 0.3 percent. Tools handle validation, not generation.
Teams that start with Semrush and stop there end up with a long-tail map that any other team could build with the same tool license. The differentiation comes from sources 1 through 3.
Long-Tail Discovery Checklist (How to Find the Most Valuable Long-Tail Keywords)
A 10-point checklist we hand to clients in the first sprint. Tick each one off before any page gets briefed.
1. Pull the last 30 days of recorded discovery calls. Tag every prospect phrasing that names a specific problem.
2. Export Zendesk or Intercom tickets from the last 90 days. Cluster ticket subject lines by buyer state.
3. Run a 60-minute interview with two senior AEs. Capture the exact pricing and security questions buyers ask in week one of the cycle.
4. Pull the last 20 win-loss interview transcripts. Highlight the comparison phrasing buyers use to describe the shortlist.
5. Prompt ChatGPT and Perplexity with the three layer-specific templates above. Save the surfaced queries in the cluster intent map.
6. Mine Reddit (the top three subreddits for your category), Indie Hackers, and one niche Slack community. Pull operator-phrased queries.
7. Export Google Search Console queries from the last 16 months. Filter for queries with under 50 impressions and a position between 11 and 30.
8. Validate every candidate query in Ahrefs or Semrush. Drop queries with zero validated search volume but keep "valuable-zero-volume" candidates (operator-phrased queries that rank but do not appear in volume tools).
9. Classify every surviving query against the four layers. Drop Layer 1 queries that cannot be made citation-eligible.
10. Map every surviving query to a cluster cell in the intent map. Confirm no two pages target the same buyer state in the same cluster.
Live SaaS Pages Worth Studying
Walking page anatomy in the abstract only gets you so far. The pages below are public, indexed, and live as of 2026. Open each one in a new tab and study what they do well before briefing your own version.
Layer 3 vendor-evaluation pages worth studying:
- Pricing pages: Linear pricing (clean plan tiering with seat-based ROI), Notion pricing (use-case-first plan framing), HubSpot pricing (multi-product bundle clarity).
- Security pages: Datadog security (certifications above the fold, architecture diagram, sub-processor list), Stripe security (compliance matrix by region).
- Compliance pages: Linear trust (audit reports gated for buyers, SLA detail), Vanta trust (continuous monitoring framing).
- Integration hubs: Slack integrations (search + category navigation), Zendesk marketplace (per-integration setup time visible).
Layer 2 comparison pages worth studying:
- Linear vs Jira (comparison table with verdict scenarios).
- Notion vs Confluence (use-case-led comparison).
- Ahrefs vs Semrush (data-rich row labels).
Layer 4 jobs-to-be-done operator pages worth studying:
- HubSpot's "how to write a marketing plan" (operator question + tool integration + downloadable artifact).
- Ahrefs' "how to do keyword research" (step-by-step with tool screenshots).
- Stripe Docs (operator how-to with embedded code samples).
Utility tools worth studying for backlink leverage:
- HubSpot Make My Persona (single-purpose interactive tool).
- Ahrefs Free SEO Tools (suite of free utilities driving 60K+ backlinks).
- Calendly Meeting Cost Calculator (calculator with embedded brand).
Study each page for its direct-answer opener, named entities, schema, and the specific element that makes it citation-eligible. The patterns travel across categories.
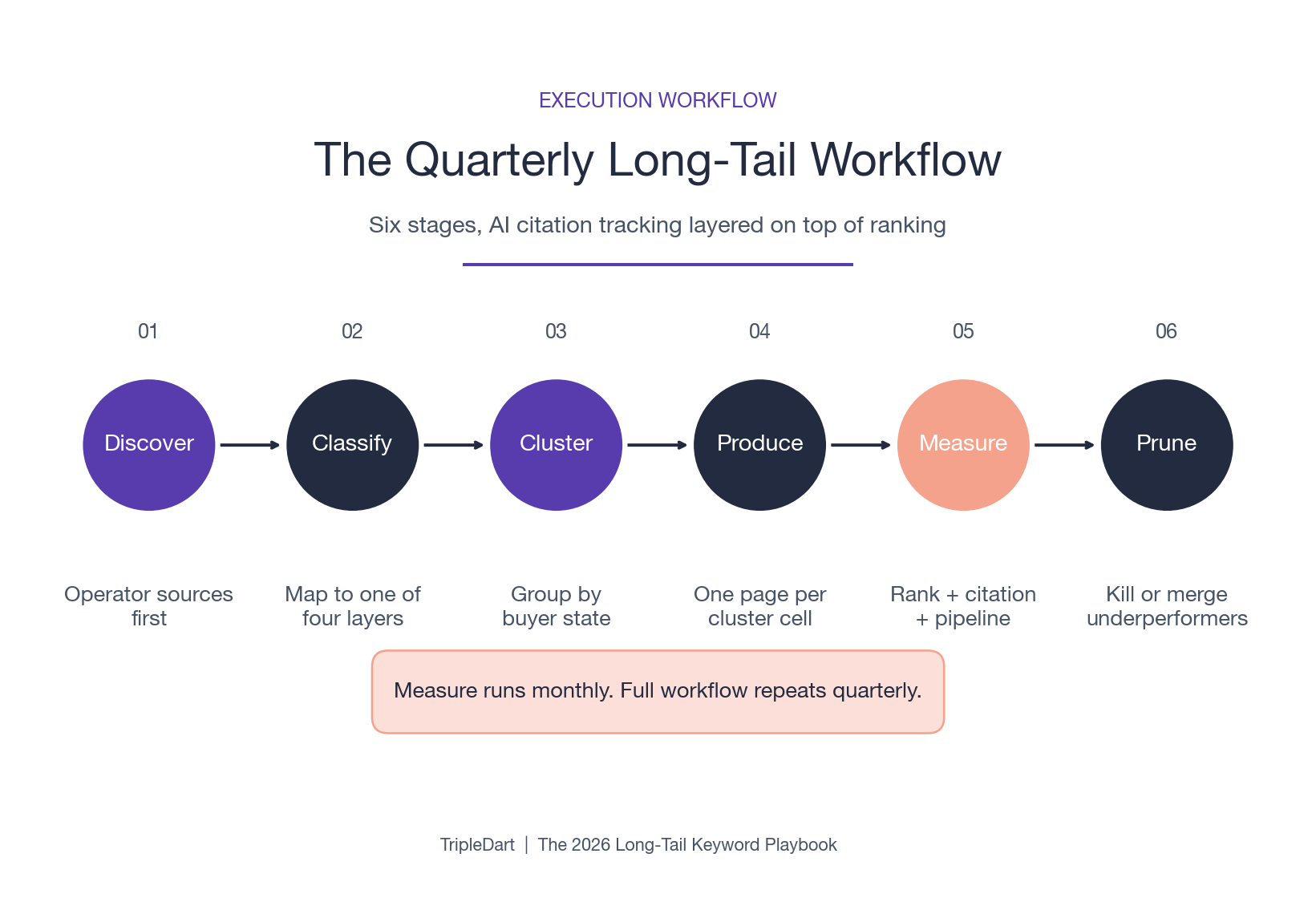
How to Run a Quarterly Long-Tail Keyword Workflow
The teams that grow long-tail revenue past Month 12 run a quarterly workflow with AI citation tracking layered on top of ranking measurement. The workflow has six stages, and each stage feeds the next.
- Discover in the order described above, operator sources before tools.
- Classify each query against one of the four layers.
- Cluster queries by buyer state, not by surface-level topic similarity.
- Produce one page per cluster cell with the layer-appropriate page architecture.
- Measure ranking, AI citation share, and pipeline attribution as three separate signals.
- Prune underperformers at the cluster level so the portfolio stays clean.
The cluster intent map (the Airtable or Notion schema we hand to clients):
The citation-tracking half of measurement is where most SaaS teams have a gap. Tracking ranking in Semrush is operational hygiene. Tracking which pages get lifted into Perplexity, ChatGPT, and Google AIO answers is the leading indicator of branded search lift two quarters later.
The KPI dashboard fields. Per-page, tracked weekly or monthly:
- Position (Search Console).
- Impressions (Search Console).
- Clicks (Search Console).
- CTR delta vs prior month (calculated).
- Branded search lift vs 90 days ago (Search Console "brand" segment).
- Citation count in Perplexity for 10 anchor queries (manual or via a citation-tracking tool).
- Citation count in ChatGPT for the same 10 anchor queries.
- AI Overview presence on the page's primary query (Search Console + manual check).
- MQLs attributed to the page (HubSpot or Salesforce, last non-direct touch).
- Demos attributed to the page (same source).
When we audit SaaS sites that have stopped growing on long-tail, we typically find that 20 to 35 percent of their existing pages are AI-citation candidates after a structural pass. Another 10 to 15 percent are already getting cited without anyone tracking it.
The Citation Visibility Gap We See Most Often
The citation visibility for a typical SaaS content program ranges from 8 to 18 percent of total branded answer surfaces in its category. Programs that ship a citation-tracking workstream alongside ranking workstreams typically push citation visibility past 30 percent inside two quarters, with branded search lift following 6 to 10 weeks later.
The cadence we run with clients runs at three speeds:
- Weekly for ranking checks, Search Console anomaly review, cannibalization flag scan.
- Monthly for AI citation tracking, branded search delta review, pipeline attribution rollup.
- Quarterly for cluster health audit, prune decisions, new cluster planning.
Most SaaS teams skip the monthly cadence and find out their citation share dropped only at the quarterly review.
By that point a competitor has been picking up the citations for two months. The cadence is the part most often abandoned when a content program is under headcount pressure.
What SaaS Long-Tail Programs Look Like at Scale
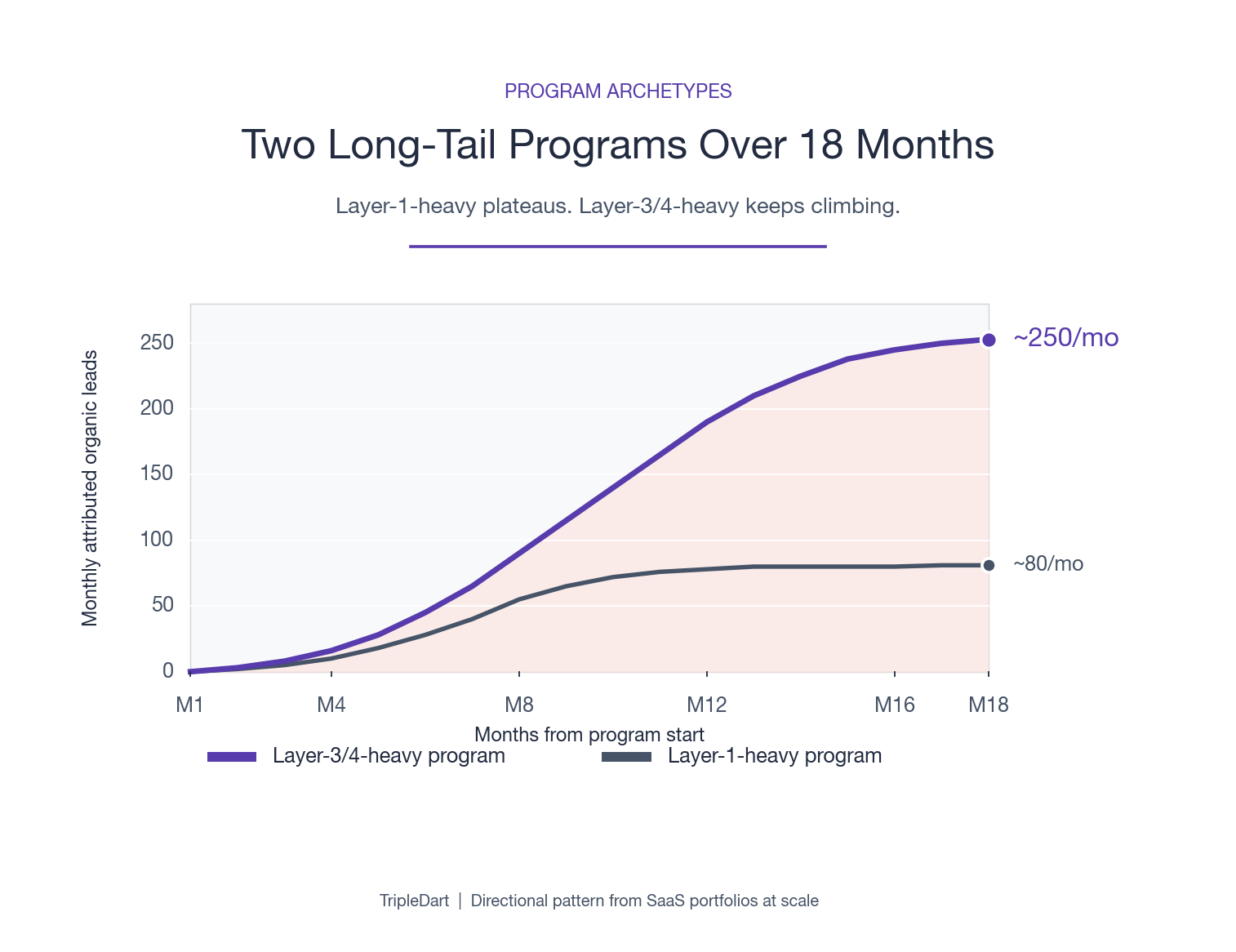
The portfolio patterns below are directional and useful as planning benchmarks. They show up consistently across categories from observability to billing to revenue operations.
1. Layer 3 and 4 clusters double Layer 1 pipeline: Clusters built around vendor-evaluation and operator pages produce roughly twice the year-one pipeline of clusters built around problem-state pages, on similar content investment. Layer 3 and 4 pages convert closer to the demo decision, so a single ranking win produces more pipeline.
2. The citation curve bends in months 6 to 9: For moderate-difficulty SaaS categories, well-built clusters start producing measurable lift between months 6 and 9. Sites with prior topical authority bend the curve earlier. Sites starting from zero need 9 to 14 months. Programs pulled at month 6 because the curve has not yet bent are the most common failure mode we see.
3. Measurement gaps kill programs before content gaps do: Two SaaS teams can publish the same number of pages on the same keyword list and produce different pipeline outcomes. One team can attribute pipeline back to specific pages and queries. The other cannot. Without attribution, the program does not survive the budget review at month 12.
4. Layer 1 over-investment is the most common operator mistake: Teams find Layer 1 queries more easily through keyword tools because the SERP is well-mapped. They find Layer 3 queries harder to surface without operator input. The portfolios that scale invert the time allocation: 60 percent of writing hours on Layer 3 and 4, 30 percent on Layer 2, 10 percent on Layer 1.
Budget math for a 40-page cluster. The directional cost breakdown we use with clients:
A 40-page cluster that produces 18 to 32 monthly demos at month 12 typically delivers a payback of 3.5x to 7x in year two, depending on ACV. The math holds for ACVs above $12,000. Below that, the unit economics need a different page mix.
Edge cases and trade-offs.
- PLG SaaS: The Layer 4 weighting goes up because operator queries convert directly to self-serve sign-ups, often without a demo. The Layer 3 weighting drops because pricing is on a public page that handles its own conversion. Target mix: 15-20-30-35.
- Sales-led enterprise SaaS: The Layer 3 weighting goes up because enterprise buyers need security, compliance, and procurement-grade documentation pages. Target mix: 10-25-45-20.
- Regulated industries (fintech, healthtech): Compliance pages dominate Layer 3 and need legal review per page. Add 30 to 45 percent to per-page production cost.
- International expansion: Each region needs a Layer 3 data residency page and localized comparison pages. Translation costs roughly $1,200 to $2,000 per page.
The Anti-Patterns That Sink Long-Tail Programs
We see the same five mistakes in roughly two-thirds of the stalled long-tail programs we audit. Each one is correctable inside a single sprint if the team agrees to act on the diagnostic.
1. Publishing Layer 1 content with no citation architecture: The page is built for clicks. AI Overviews take the clicks. The page produces neither traffic nor citations. The fix is a one-pass structural rewrite for citation eligibility, not a new page.
2. Treating the cluster intent map as optional: Without classification at the start, two pages collide in the SERP within six months. The team writes a third page to "settle the issue" and now three pages compete for the same query. The fix is the Monday cannibalization scan plus the cluster map upfront.
3. Outsourcing operator-source discovery: A freelance keyword researcher cannot get on a sales call. The queries that pull from internal sources never enter the brief. The fix is a recurring 90-minute monthly session with sales and CS.
4. Tracking ranking without tracking citation visibility: The team celebrates a #3 ranking that has an AI Overview above it and produces 40 percent fewer clicks than it would have in 2022. The fix is to add citation tracking to the weekly Search Console review.
5. Pulling the program at month 6 because the curve has not bent: The Phase 2 patience window is the most under-respected variable in any SaaS organic program. Programs cancelled at month 6 to 8 routinely show up in our audit work two years later when the team has tried and abandoned three replacement programs. The fix is to publish the expected curve shape in the board deck on day one.
Putting the Long-Tail Strategy Into Practice
The long-tail strategy that holds up in 2026 has four moving parts working together:
1. Citation eligibility as the unit of analysis: the metric that replaces ranking position when AI engines intercept the answer.
2. A four-layer conversion model with distinct page anatomy per layer: problem-state, comparison and alternatives, vendor-evaluation, jobs-to-be-done.
3. Cluster economics that make the math defensible: rollup pipeline math that holds up in front of a CFO at the budget review.
4. A quarterly workflow with AI citation tracking, weekly Search Console review, and Monday cannibalization scans: the operating cadence that keeps the program funded past month 9.
The teams that hold all four together produce SaaS organic lead curves that keep paying off through year two and three. The teams that hold only one or two find their curves plateau.
TripleDart runs the SEO and GEO programs that produce these curves for 250+ B2B SaaS portfolios. The brands behind that work include SignEasy, SpotDraft, and Helpshift.
If your long-tail program has stopped paying off, book a strategy call to walk through how the citation-and-conversion model would apply to your category.
Frequently Asked Questions
What is the difference between a long-tail keyword and a long-tail keyword strategy?
A long-tail keyword is one query with low volume and specific intent. A long-tail keyword strategy is the system that maps hundreds of those queries to a conversion stage, a content cluster, a workflow, and a measurement layer. The strategy is the asset. The keywords are the inputs.
How many long-tail keywords should a SaaS site target in year one?
A SaaS portfolio that keeps paying off through year two typically targets 120 to 280 long-tail queries across 30 to 60 cluster cells in year one, then roughly doubles in year two. The right number is set by cluster economics and category density, not a fixed target.
Are long-tail keywords still worth the investment with AI Overviews intercepting clicks?
Yes, but the measurement target moves. A citation-eligible page produces brand pull through AI Overviews even when its click-through rate drops.
The pull shows up in branded search and direct demo bookings four to eight weeks later. The AEO vs SEO guide covers the structural difference.
How do you classify a long-tail keyword by intent?
Map the query to one of four layers: problem-state, comparison or alternative, vendor-evaluation, or jobs-to-be-done operator. The layer determines the page type, the call-to-action, and the measurement target for the page.
What is the best tool for finding long-tail keywords for a SaaS site?
No keyword tool beats operator sources for finding the highest-converting queries. Sales call notes, support tickets, and win-loss interviews surface the queries buyers really type.
Tools like Ahrefs and Semrush are reliable for volume validation. The order of sources counts more than the tool choice.
How long does a long-tail keyword strategy take to pay off in pipeline?
The citation visibility curve typically bends in months 6 to 9 for moderate-difficulty SaaS categories. Sites with prior topical authority bend the curve earlier. Sites starting from zero need 9 to 14 months. The pipeline curve follows the citation curve with a 6 to 10 week lag.
How is a long-tail keyword strategy different in 2026 from the one SaaS teams ran in 2022?
Three changes drive the difference:
1. AI Overviews now intercept 30 to 60 percent of the click-through on long-tail informational queries.
2. The answer surface now includes ChatGPT, Perplexity, and Gemini, so structural signals AI engines weight (named entities, direct-answer openers, structured data) drive visibility.
3. Conversion-stage classification carries more weight because there are fewer chances to capture a buyer per query, so the page architecture has to be right the first time.
How do you measure AI citation visibility for a long-tail page?
Track 10 anchor queries per page in Perplexity and ChatGPT. Check monthly whether the page is cited as a source in the answer.
Roll up at the cluster level. Pair with Search Console branded search delta to see whether the citations are producing downstream lift in branded queries 6 to 10 weeks later.
What is the typical budget for a 40-page long-tail cluster in year one?
Year-one cost runs $48,000 to $75,400 for a 40-page cluster, covering writing, SEO and GEO editing, schema engineering, design, citation tracking, and quarterly audits.
The math holds for SaaS sites with ACVs above $12,000. Below that, the page mix needs to move toward higher-leverage Layer 4 templates.
.jpeg)
summarize with ai




