.png)

Yesterday, Anthropic shipped Claude Opus 4.8.
It landed forty-one days after 4.7, quick even by this year's pace.
Most of the coverage went straight to the coding score. The model now catches its own mistakes far more often, and stops handing you shaky work dressed up as finished.
If you have ever pasted an AI draft into a doc and then gone hunting for the source of a stat it stated with total confidence, that sentence is the whole release.

Anthropic's launch art for Opus 4.8.
The story
Opus 4.8 is the newest version of Anthropic's flagship model.
The launch post says early testers found it "more reliable and sharper in its judgement" on agentic tasks, and that it is "more likely to flag uncertainties about its work and less likely to make unsupported claims."
Price held flat against 4.7, at five dollars per million input tokens and twenty-five per million output.
Two new controls came with it:
- Effort control lets you choose how hard the model thinks on a task.
- Dynamic Workflows, in research preview inside Claude Code, lets it plan a job and run hundreds of agents at once.
Anthropic also teased a higher tier called Mythos for the coming weeks.
The model was not the only thing Anthropic put out that day.
The same afternoon it closed a $65 billion round at a valuation near $965 billion, the largest any AI company has raised, as Bloomberg reported. That pushes it past OpenAI and within reach of a trillion dollars, with an IPO now in view.
For a marketer the takeaway is simple. The platform you would wire into your content pipeline is now the most valuable AI company on the board, with the cash to outlast your next several planning cycles. Pricing held flat through this release. Whether it stays flat once the IPO clock is running is the open question.
So on paper it reads as a steady mid-cycle bump.

The release in four numbers.
The ‘honesty’ number is the one to read first
Anthropic says Opus 4.8 is around four times less likely than 4.7 to let flaws in its own work pass unremarked.
Its own misaligned-behavior score backs that up: 4.8 sits well below 4.7, closer to the unreleased Mythos preview than to the model it replaces.
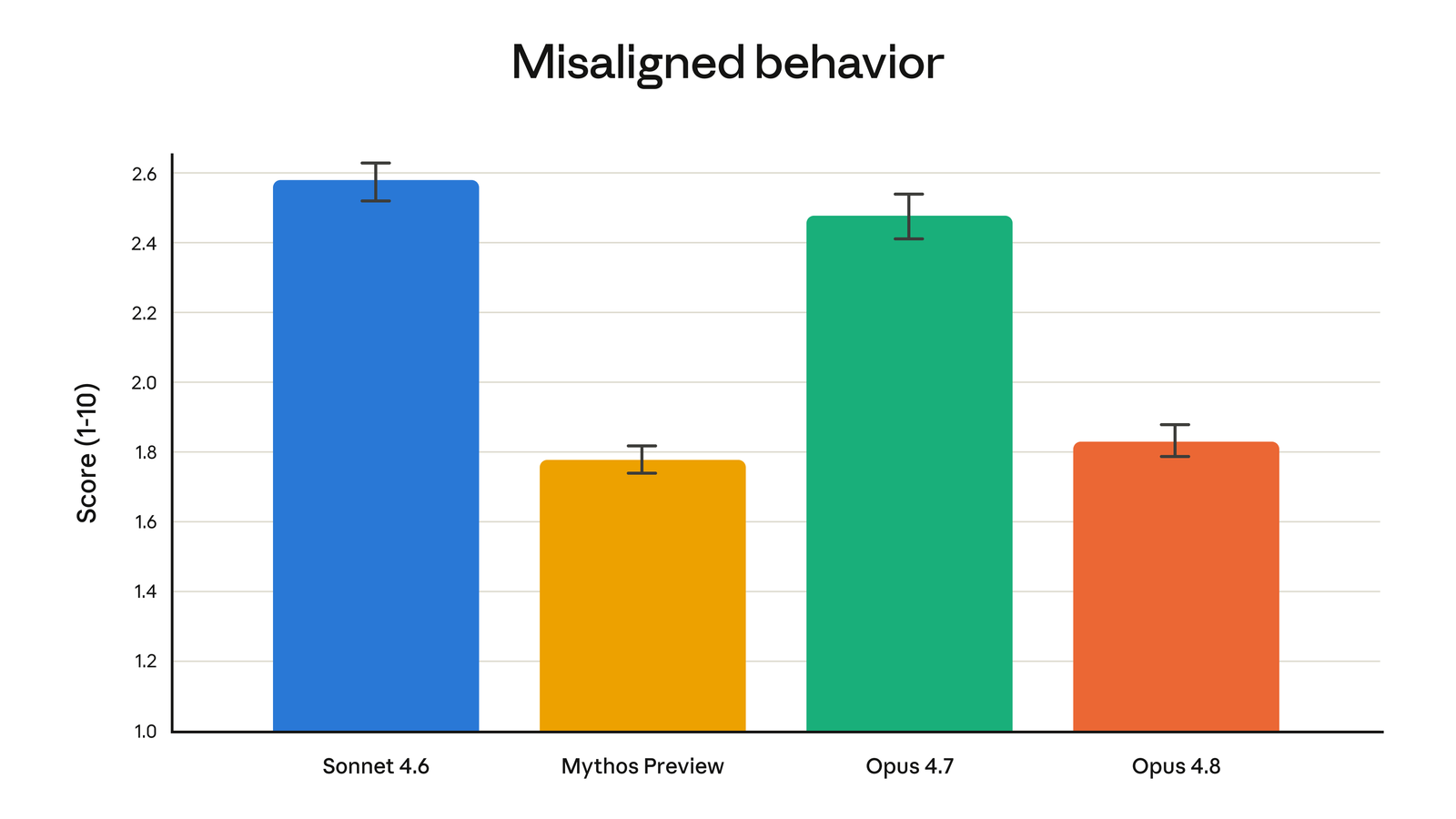
Anthropic's misaligned-behavior score, where lower is better. 4.8 drops below 4.7 and lands near the Mythos preview.
The benchmarks moved the way you'd expect alongside that.
Agentic coding climbed from 64.3 to 69.2 percent and the knowledge-work index went from 1753 to 1890, as 9to5Mac logged.
Bridgewater, the hedge fund, told Anthropic the biggest difference was the model proactively flagging issues with the inputs and outputs of an analysis, TechCrunch reported.
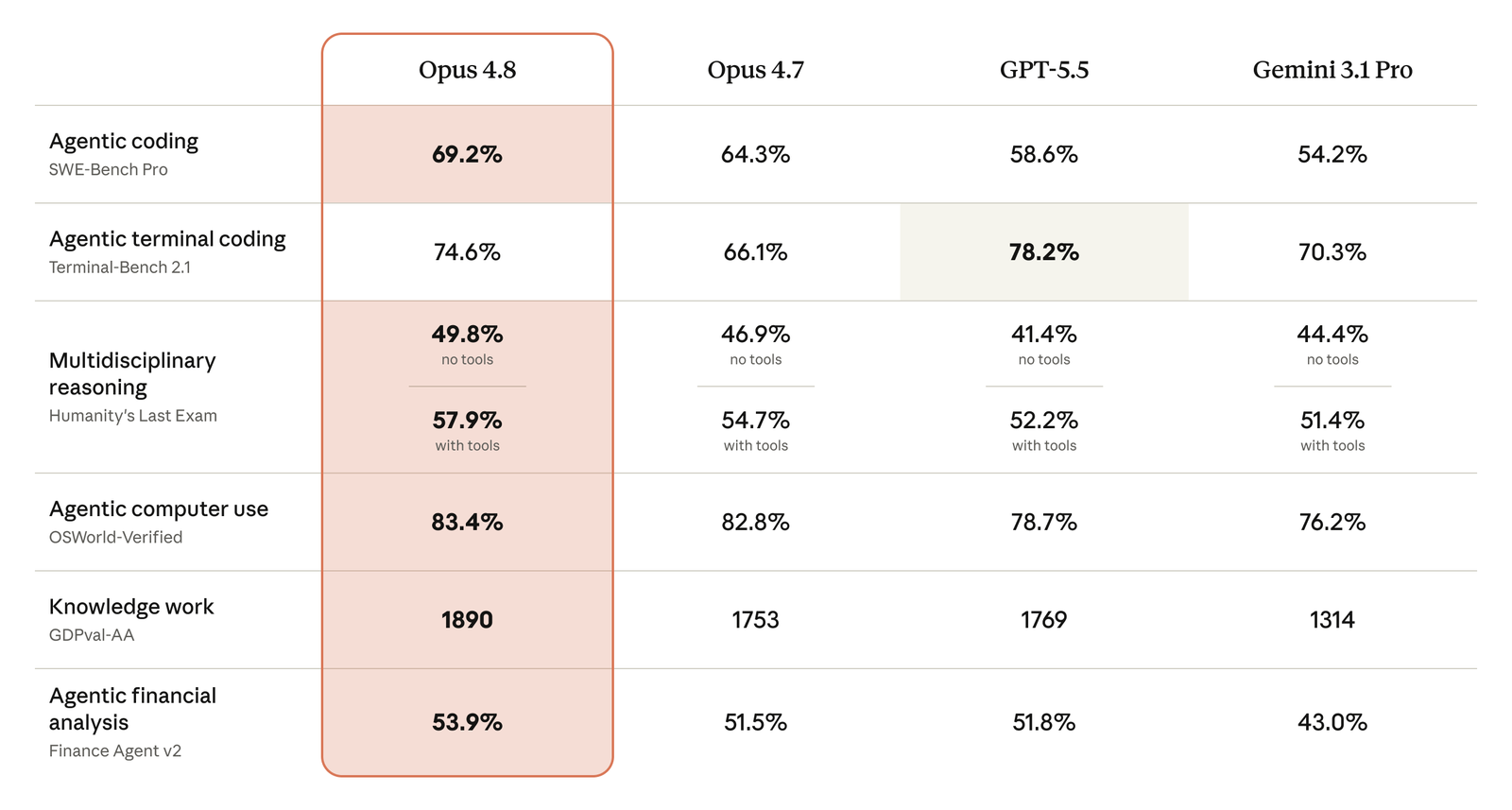
Opus 4.8 against 4.7 and the current frontier from OpenAI and Google. Every category Anthropic published moved up over 4.7.
Here is why that number outranks the coding score for a marketer:
The failure mode that has kept AI out of serious content work was never speed. It was confidently wrong. A clean paragraph, a stat nobody sourced, and it surfaces weeks later when someone quotes your own blog back at you and the figure is off.
So you learned to babysit it. Read the draft twice, trace the numbers before they ship. The model saved you the first draft and handed you the fact-check in return.
A model that says "I'm not sure about this figure" is worth more to that workflow than a model that drafts faster. It doesn't end the review. It thins it out, so the human checks the few flagged exceptions instead of re-reading every line on suspicion.
Hundreds of agents in one session
Dynamic Workflows has the biggest ceiling here.
Inside Claude Code, Anthropic's terminal tool, the model can plan a task and run hundreds of agents in parallel within one session. The example Anthropic led with was a code migration across hundreds of thousands of lines, kickoff to merge.
Swap "codebase" for "content library" and the marketing version comes into view.
Think about the job you keep moving to next quarter. The site-wide audit that meant opening one URL at a time. Or the few thousand product pages with meta descriptions nobody has touched since launch.
None of that was ever hard. It was just too big to hand a single chat window, so it sat on the someday list.
The bottleneck in most content teams was never the writing. It was doing the unglamorous work at scale, one tab at a time. Run a few hundred of those passes in parallel and the someday list starts to look like a Tuesday.

Four changes in 4.8 and where each one earns its keep on a marketing team.
Pay for thinking only where it counts
Effort control is the change most teams will feel in the invoice. You pick how hard Opus 4.8 works on a request, from standard for routine drafting up to max for the analysis you cannot get wrong. The setting sits right next to the model picker in claude.ai and Cowork, so you choose it per task.
And fast mode, the quicker tier, now runs about 2.5 times faster and roughly three times cheaper than it did on earlier models, at the same headline price.
For the high-volume, low-stakes grind, the alt text, ad variants, internal-link suggestions and first-draft meta descriptions, that combination is what moves them from "too expensive to bother automating" to "run the whole backlog tonight."
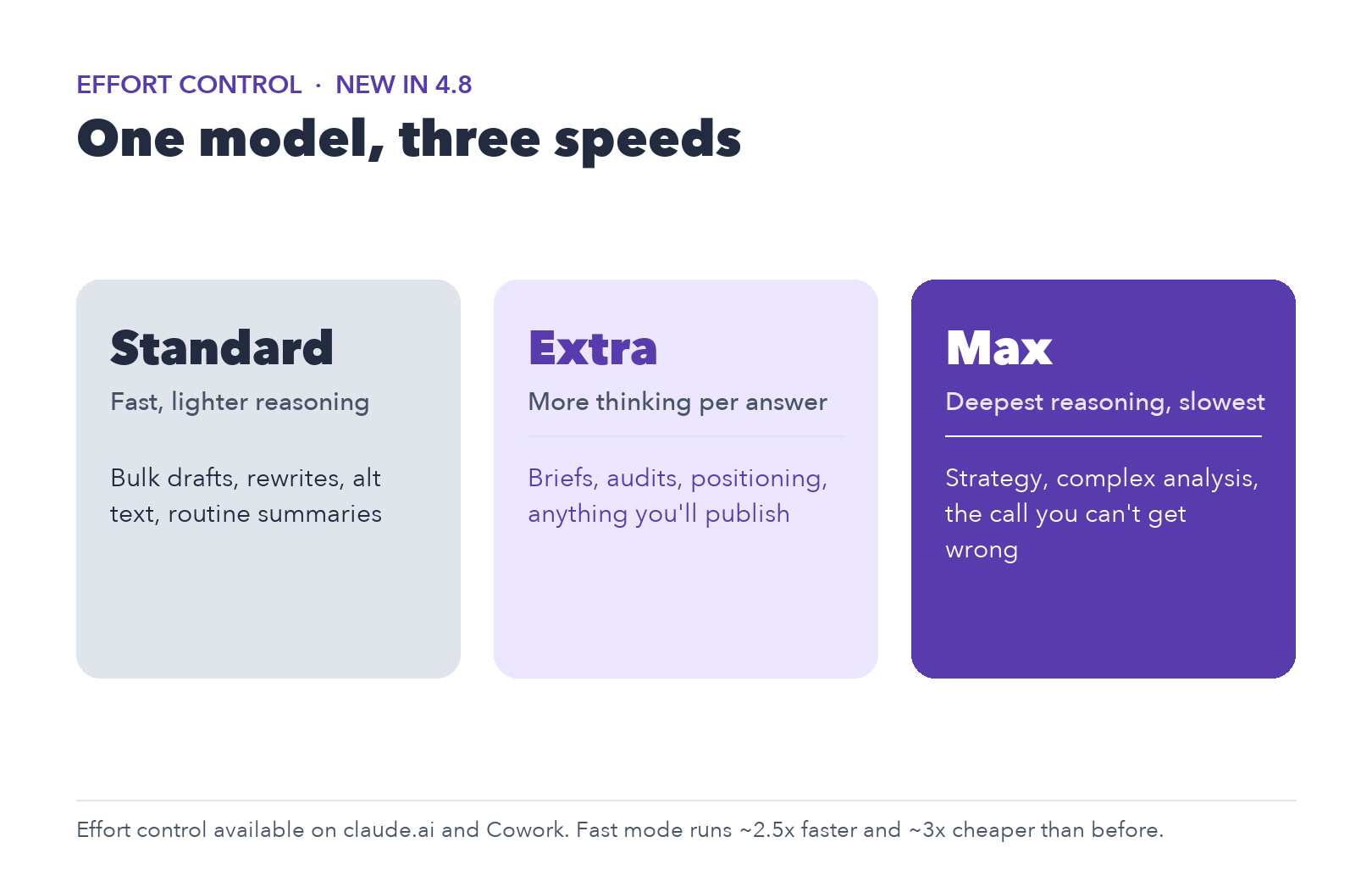
One model, three effort levels. Match the setting to what a wrong answer would cost.
What we'd run this week
If you want to act on Opus 4.8 instead of just reading about it, here's where to start.
- Put the fact-check inside the draft: The honesty gain means a verification pass can run while the piece is still being written, not after. Wire it into the brief-to-draft step so weak claims get flagged before an editor ever opens the doc.
- Pick one library-wide job you've been avoiding: A meta-description refresh across a neglected blog, or a positioning sweep of an aging resource center. Hand it to a single Dynamic Workflows session instead of a quarter of someone's calendar.
- Set effort by what a wrong answer costs: Standard speed for the bulk grind, max for the analysis going in front of a board. You pay for depth only where being wrong has a price.
- Re-cost your AI line items: Fast mode running roughly three times cheaper changes which tasks clear the bar for automating at all. Work that wasn't worth the spend last month might clear it now.
Opus 4.8 is a steady upgrade with one outsized feature for marketers: you can trust more of what comes out without watching every token go by.
If any of these are live on your team this quarter and worth comparing notes on, let’s talk..
Until the next one.
.webp)




















