.png)

A model you can leave running for hours.
That's the pitch Anthropic put behind Claude Fable 5 this week. The benchmark numbers are high, and for once they hold up against the figures rival labs put out themselves. But the part that matters for a marketing team is the time: Fable 5 is built to take a job, plan it, work at it for hours, and come back when it's done.
The story
On June 9, Anthropic released Claude Fable 5, the first model it has sold from a new top tier it calls Mythos-class. Until this week that tier was restricted to a small group of cybersecurity defenders and critical-infrastructure operators under a program called Project Glasswing.
When we covered Claude Opus 4.8 for marketers two weeks ago, Anthropic had teased a higher tier called Mythos for the coming weeks. This is that tier.
Fable 5 and the restricted version, Mythos 5, are the same underlying model. The difference is a layer of safety filters.
When Fable 5 reads a request in a few high-risk areas, offensive cybersecurity, biology, chemistry and a couple of others, it blocks its own answer and hands the question to Opus 4.8 instead. Anthropic says that fallback fires in under 5% of sessions. Everywhere else, you get the full model.
Two months ago the company said a model this capable was too dangerous to release widely. Its position now is that the filters, which held up through a 1,000-hour external bug bounty and outside red-teaming without a universal jailbreak, make broad access fair to offer. Reasonable people came down on both sides this week.

What it's built for
Fable 5 is built for long, multi-step work that used to be too big to hand a chat window. Anthropic says it can run inside an agent like Claude Code for days at a time, planning its approach, checking progress against the goal, handing pieces to sub-agents, and revising as it goes.
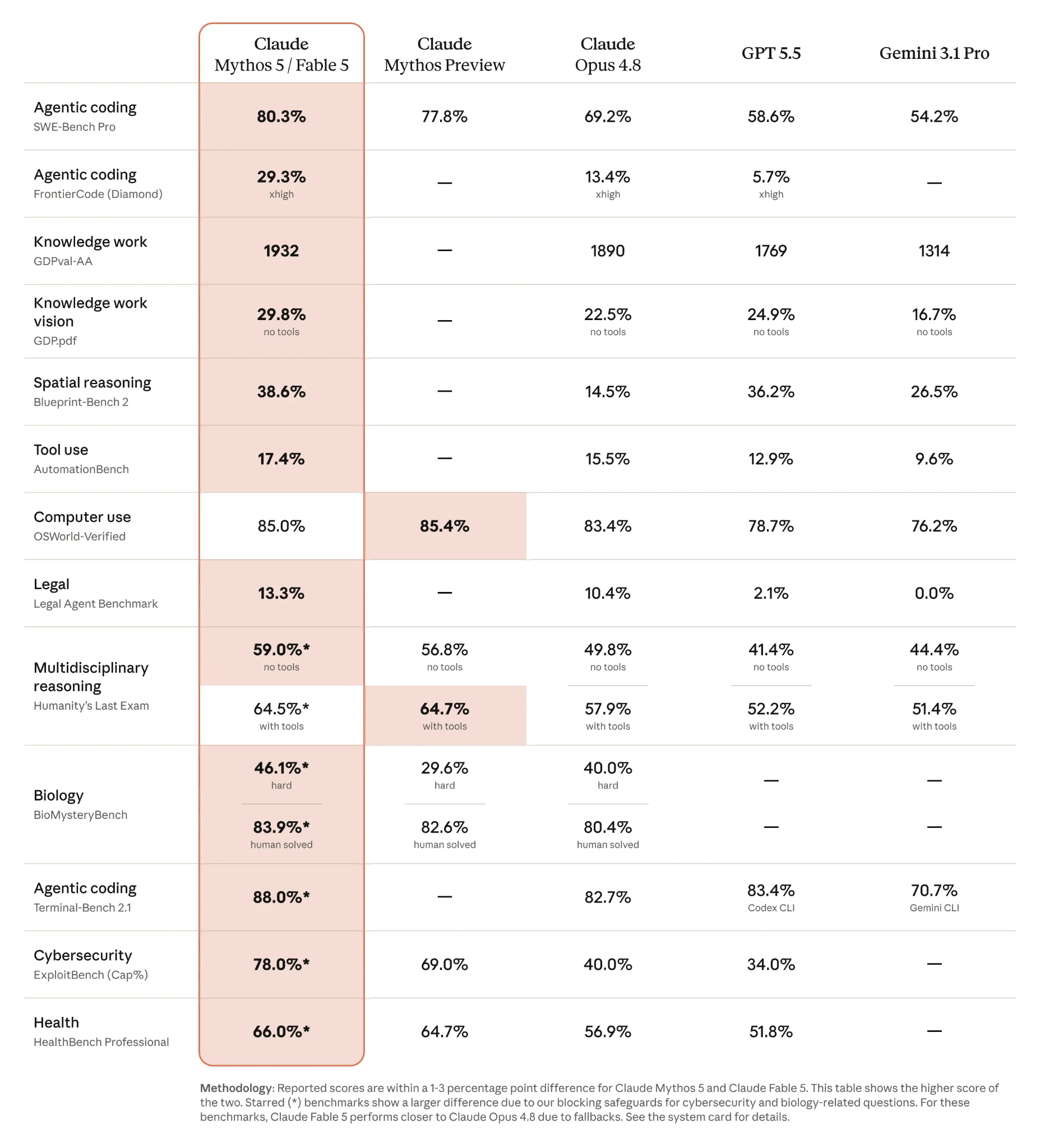
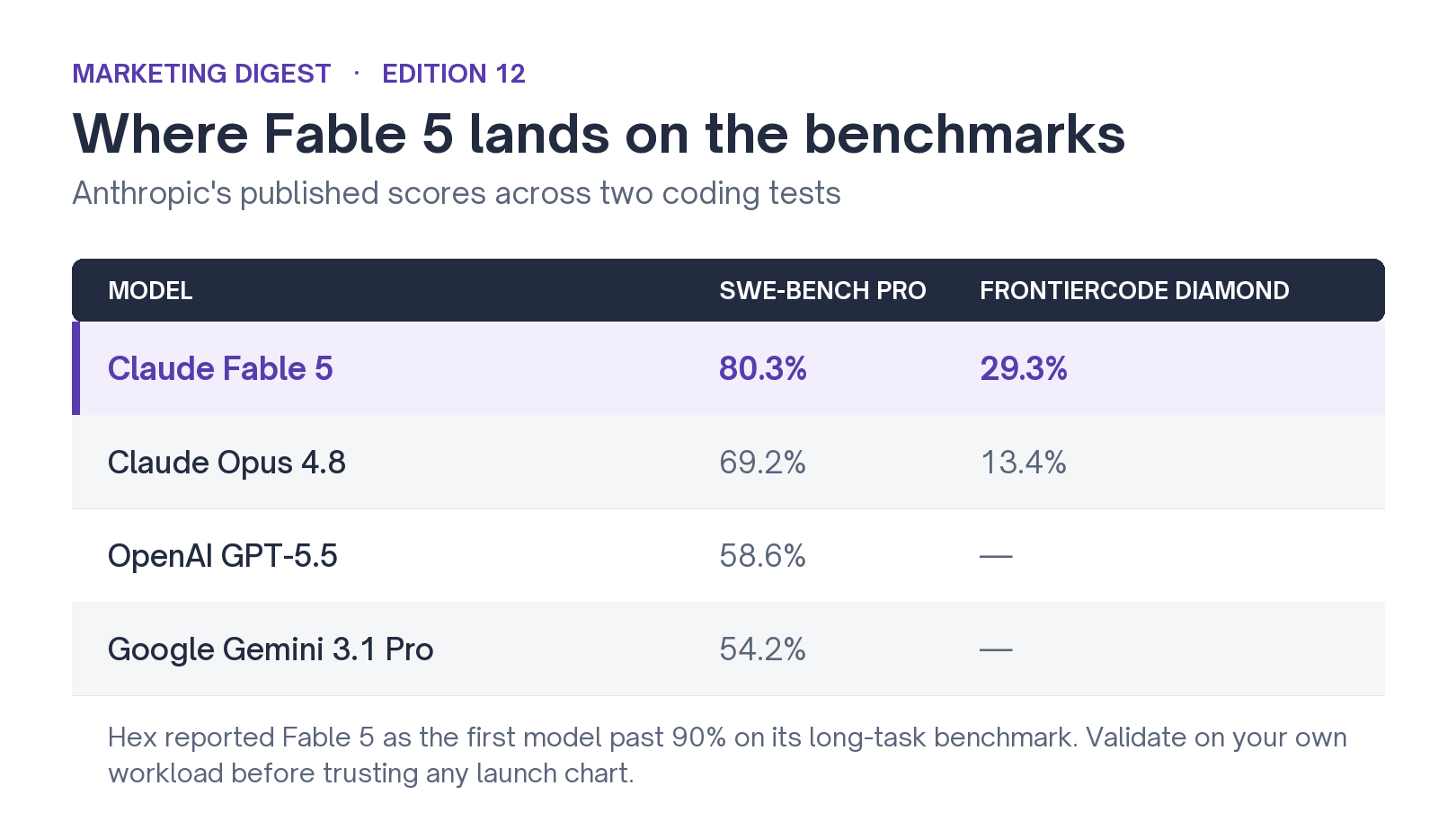
The benchmark gap backs that up, and it's widest where the work is longest. On SWE-Bench Pro, Anthropic's headline coding benchmark, Fable 5 scores 80.3% against Opus 4.8's 69.2%. The jump from Opus to Fable is bigger than the jump from Opus to Google's Gemini. On a harder long-task set, the margin is wider still: 29.3% against 13.4%. GitHub and Cursor, both early testers, reported the same on long-horizon jobs: reliability past anything they had benchmarked before.
Opus 4.8 shipped with Dynamic Workflows, where one session plans a job and runs hundreds of agents at once. Fable 5 is the model built to finish them.
Swap the codebase for a content library and the marketing version comes into focus. It's the site-wide audit you currently open one URL at a time, or the migration off an aging CMS that never made the quarter's plan.
That's the whole pitch: a model you can walk away from.
What it costs to run
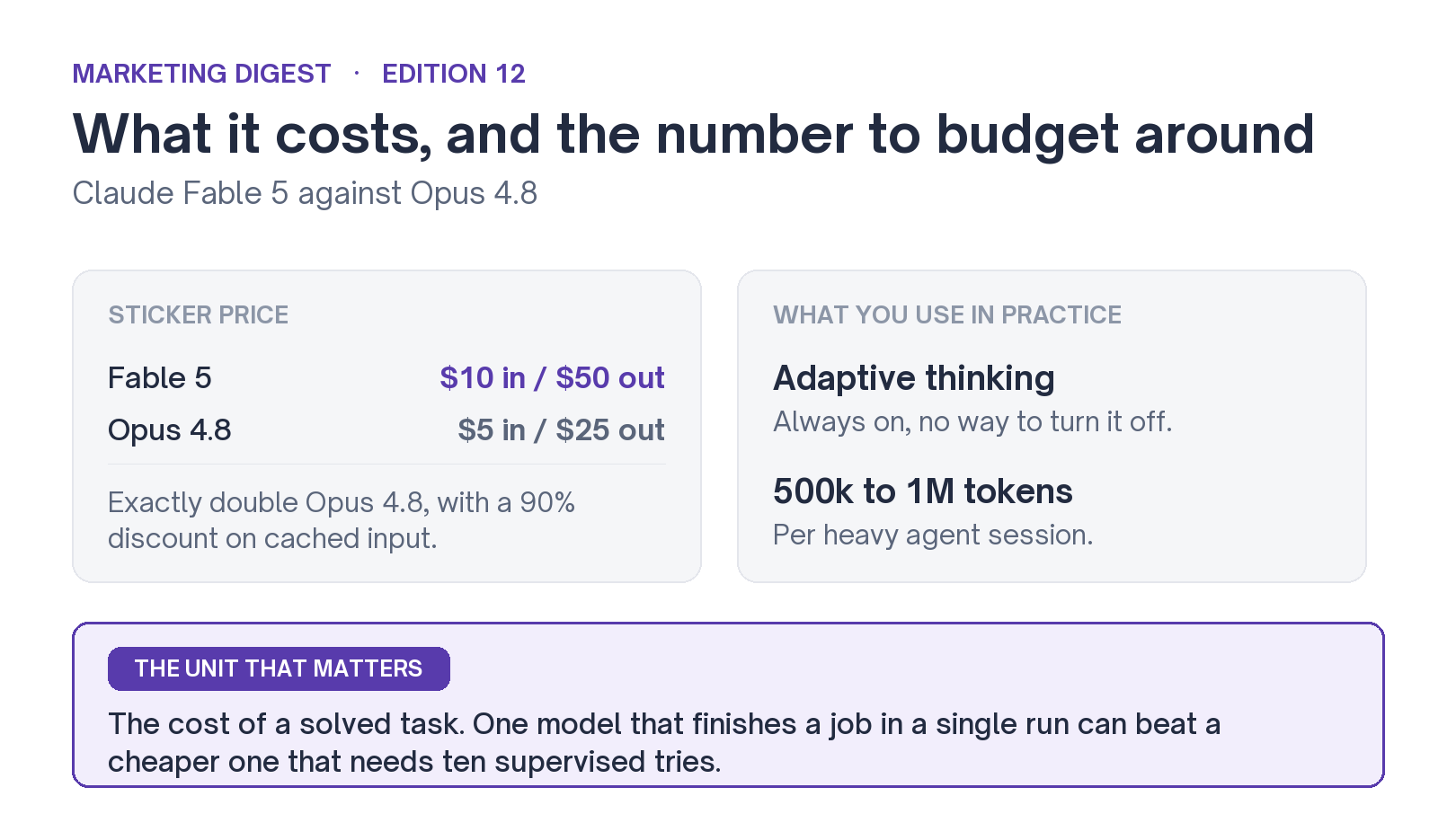
Fable 5 costs $10 per million input tokens and $50 per million output, exactly double Opus 4.8, with a 90% discount on cached input. The model string is claude-fable-5, and it's live on the Claude API, Claude Code, Amazon Bedrock, Google Cloud, Microsoft Foundry and GitHub Copilot.
The sticker price undersells what you will spend. Adaptive thinking is always on, and early users report heavy agent sessions running through 500,000 tokens to a million at a stretch. The unit that matters, as CodeRabbit's review put it, is the cost of a solved task. A model that finishes a migration in one unsupervised run can come in cheaper than a cheaper model that needs ten supervised tries.
When Anthropic filed to go public on June 1, we said usage prices now have a floor under them. A model priced at double the last one is that floor moving up.
One scheduling note. Fable 5 is in Pro, Max, Team and seat-based Enterprise plans only through June 22, then it moves to usage credits until Anthropic has the capacity to fold it back in. If you want to test it on subscription pricing, the window is short.
When to reach for it
Fable 5 is worth reaching for on heavy, long-running work and overkill for everything else. The split is clean enough that early users agree on it almost across the board.
Where it's worth the spend:
- Large refactors and migrations, including one early report of a job across a 50-million-line codebase finished in a day.
- Long-running research and analysis that needs a plan held over hours.
- Multi-stage projects where the model has to keep a goal in view across a working day.
- Frontend and design work, where several testers said the output no longer looks obviously AI-made.

Where it doesn't earn its place: the quick questions and the routine drafting, where you need an answer back in seconds. In his first impressions, Simon Willison called it a beast that is also slow and expensive, happy to churn through everything he gave it, with the trick being to find tasks hard enough to be worth the spend. For everyday work, Opus 4.8 or Sonnet stays the rational default.
The praise is loud. Andrej Karpathy called it a step change that earns its major version number, and Ethan Mollick said an early version produced genuinely sophisticated work.
The criticism is worth holding too. CodeRabbit found Fable 5 matched Opus 4.8 at catching genuine issues but left far more comments at lower precision, so more to sort through. Mollick noted it explains little about the choices it makes inside a long task. And the model card showed Anthropic now limits the model on requests tied to frontier AI development and enforces it without telling the user.
Where this goes next is the work itself. We are starting to hand Fable 5 the long, unglamorous jobs that sit on the someday list, the kind we already run through Claude but bigger, library-wide audits and CMS migrations, and watching whether one unsupervised run beats ten supervised ones. For most everyday work the answer is still the older models. But if you have a job long and hard enough that a model working on its own for an afternoon would clear its own bill, pressure-test it with us.
More once the bills come in.
.webp)




















