.png)


TripleDart Q2 2026 Field Report at a glance: 250+ B2B SaaS clients globally, more than $150M in ad spend managed across the book, more than $50M in pipeline tracked through Q2 alone, 60 days of telemetry from March 8 to May 8, 2026
The Pattern We Couldn't Stop Seeing in Q2
Three signals came back from three different SaaS pools we analyzed this quarter. On the surface, they had nothing in common.
Across paid programs we benchmarked, dashboards were missing CVR drops that a daily check on the same account would have caught the next morning. In SEO reads we ran across the category, click and impression lines on the same page were drifting apart inside the same reporting week. In RevOps audits we conducted on prospect and partner stacks, closed-won numbers had stopped reconciling weeks before anyone on those teams had noticed.
We sat with these signals for a while. They looked unrelated. They weren't.
The cadence at which marketing decisions get made has tightened sharply over the last two years. Most of the operating cadences in B2B SaaS are still set up for the speed teams were running at in 2024. That's the gap.
We work with 250+ B2B SaaS companies on SEO, content, paid media, and RevOps. We've managed over $150M ad spend. Over the last 60 days, we tracked north of $50M in pipeline through these programs. The findings below are anonymized aggregates drawn between March 8 and May 8, 2026, taken from a mix of clients and non-clients, including audit work on prospect stacks.
What This Gap Looks Like in Practice
In 2024, a weekly performance review and a quarterly RevOps cleanup was a credible operating cadence for most B2B SaaS marketing programs. By 2026, both rhythms feel late by the time the reports hit the inbox.
The shape changes by domain. What sits underneath doesn't.
Across all three, the data is moving faster than the cadences designed to read it.
Chapter 1. The Slow Version: SEO and Content
In SEO, the gap moves slowly enough that you can watch it widen over a few weeks.
The shape we kept seeing across GSC reads this quarter was a decoupling. The click line and the impression line on informational pages had stopped moving together. Impressions held or grew. Clicks didn't.
A few numbers from the SEO and content book:
- 115 to 190 weekly LLM-sourced sessions per active program
- 2 to 4x conversion rate on that traffic versus traditional Google organic
- +90% AI Overview impression growth on informational pages over six weeks
- Flat or declining click-through on the same pages over the same window
The dataslayer.ai analysis of AI Overview CTR impact reads almost line-for-line with what we're seeing in client GSC. Mersel AI's organic decline analysis reaches the same conclusion across a wider sample.
The implication has been uncomfortable to sit with. In programs where the weekly read still leans on rank position while the pipeline review tracks session-to-MQL ratios, the two reports have started describing different channels.

What worked in B2B SaaS SEO this quarter and what we have stopped recommending: 60 to 70% rank lift on new product-led pages within 30 days; 2 to 4x LLM-sourced session conversion rate vs traditional Google organic; +90% AI Overview impression growth on informational pages over six weeks; 596 outlets and 154M+ audience reached on a single PR-driven product launch in three days. No longer working: generic top-of-funnel content; ranking-only KPIs; brand-only spend; one-page-a-week cadence on programs with 30+ keyword backlogs.
Generic Top-of-Funnel Content Has Stopped Earning Its Keep
Where teams in the book doubled monthly content velocity this quarter, going from 10 pages a month to 20, rank lift on the new pages came in at 60 to 70% inside 30 days. That's the headline number.
The headline missed the part that did the work. The lift only landed on pages that mapped to a specific product use case the AEs were already pitching, and a named sales objection that was surfacing on demo calls.
Generic "what is X" pages on the same programs cannibalized their own AI Overview citations and converted almost nothing to pipeline. We've stopped recommending generic top-of-funnel content for B2B SaaS clients this year.
The brief itself has changed underneath. The work in 2026 looks less like the keyword brief teams used to write, and more like the buyer brief. That's why our B2B SaaS content planning starts with the call recordings, not the keyword tool.
SEO, GEO, and AEO Now Run as One Program
The new programs we signed this quarter scoped the work explicitly to four motions running in parallel:
- Traditional SEO for Google search results
- Generative engine optimization, or being cited inside Claude, ChatGPT, and Gemini answers
- Answer engine optimization, or the Perplexity citation layer
- Reddit and community distribution, to seed the user-generated mentions LLMs treat as authority signals
These started looking less like four separate initiatives and more like one program with four heads. The conversion math is what made the difference.

Why LLM-sourced sessions convert 2 to 4x higher than Google clicks: same site, same offer, two different traffic sources. Traditional Google organic shows 100 sessions in narrowing to 1 conversion (1x baseline). LLM-sourced sessions show 100 sessions in widening to 2 to 4 conversions. LLM sessions skip the early-research detour, with buyers landing past the comparison stage.
LLM sessions appear to skip the early-research detour. The buyer arrives with the question already formed, having read three or four sources before clicking through. That's the conversion gap we kept seeing on the same site, the same offer, the same reporting week.
The SaaS Intelligence research on Reddit AI citation share puts citation growth at roughly 73% in commercial categories. Our own observations across the book line up almost exactly.
Earned mentions on Reddit and third-party listicles have moved into a primary input in our launch ROI model. When we score a product launch, downstream AI Overview citation surface area sits next to PR impressions on the slide.
Programmatic glossary pages, done the right way. A couple of product launches in the book ran programmatic glossary clusters this quarter: entity-rich, narrow-intent pages built off internal knowledge bases. Early reads showed incremental non-brand discovery without any cannibalization on core money pages.
The mechanic is simpler than it usually gets framed:
Different intent layers, different ranking surfaces, no overlap.
A productized programmatic SEO sprint runs 6 to 8 weeks end-to-end and ships 200 to 800 pages depending on source data quality. We keep the cluster on a refresh cadence afterward, because programmatic without refresh tends to slowly decay over the months that follow.
When PR Becomes a Direct SEO Input
One product launch we ran this quarter went out across 596 media outlets. Potential audience reached: 154M+ inside three days. Placements landed on Yahoo Finance, AP News, Morningstar, KTLA, and Benzinga.
We track downstream DR lift and AIO citation surface area on every launch now. Both feed back into how we score the launch. The press impression number reads as the leading indicator. The DR lift and the AIO citations are the lagging ones. Those are the numbers that translated to pipeline three months later in the cohort we tracked.
Chapter 2. The Fast Version: Paid Media
In paid, the same gap runs in hours instead of weeks. A weekly cadence on paid in 2026 is starting to look a lot like a quarterly cadence on SEO did three years ago. By the time the report is on the table, the data inside it is already old.
Across the active paid book this quarter:
- Accounts running daily AI account-health agents caught CVR breaks in roughly 24 hours
- Accounts on weekly cadence took three to five days on the same problem class
- Same accounts, same media plan, same vendors. The only thing that changed was cadence, and the blast radius followed

Same CVR break, two detection paths. The Friday afternoon break that a daily AI account-health agent catches Saturday morning, a weekly reporting cadence only sees by Tuesday at 11 AM. Roughly 74 hours of clean spend signal lost on the weekly cadence, equivalent to about $25K on a $250K-per-month account.
The math under that chart is the conversation we keep having with heads of growth. A three-day blind spot on a $50K-per-month program reads as annoying. The same gap on a $250K-per-month program burns roughly $25K of clean signal into a broken funnel before anyone reads the numbers.
That math has moved daily-cadence telemetry from "competitive advantage" to "table stakes" inside our B2B SaaS PPC work.
What a Daily Account-Health Agent Catches That a Weekly Report Misses
We deployed AI agents on a chunk of the Google Ads book this quarter. They post a daily account summary directly into the client Slack channel every morning, covering pacing against budget, cohort-level CVR, search-term anomalies, cap breaches, and a recommended action queue.
On one expense management account, the agent caught a multi-cohort CVR collapse inside 24 hours and traced the cause to a conversion-tracking break on the client side, before any optimization changes were made. On a weekly cadence, that same diagnosis would have lost four to five days of clean signal, with budget running into a broken funnel until Tuesday. The daily layer is what closed that window.
The watching is what the agent handles. The thinking still sits with the strategist. When the agent flags an anomaly, the human team picks it up the same morning, validates root cause, and decides on the move. The decision-making loop is unchanged in our work. The detection loop has compressed from a week to a day.
Why Single-CTA Won 4 of 5 PLG A/B Tests
On a network monitoring account, we ran an A/B test on the brand campaign landing page. Multi-CTA control versus single-CTA treatment. The single-CTA arm drove a roughly 20% conversion rate lift on identical traffic sources.
We ran the same test on four other PLG accounts in the same window. Single-CTA won four of the five matchups.
The PLG instinct of "show the user every option" has tended to be the wrong default for paid landing pages. Picking the action that maps to the funnel stage and removing everything else has been the cleaner pattern. Demo, free trial, sandbox login, sign-up, install: one per landing page per audience. The four-button menus on top-of-funnel traffic tend to underperform across the cohort.
When Phrase Match and Broad Match Trade Places
This was the cleanest match-type signal we've seen in a while. Same expense management account, same week, two match types running side by side:
The CTR-CVR inversion (high click-through, low conversion) tends to be the clearest single signal that a match type is pulling in wrong-intent traffic. Once the inversion shows up in a search-term review, the diagnosis writes itself.
The playbook on this pattern: pause the underperforming phrase set, lean into tightly themed exact match plus curated broad match, hold the line with negative-keyword discipline, and rebuild the search-term review into a weekly standing meeting.
Search Engine Land's PMax B2B best practices cover the broader bid-strategy implications well if you want to go deeper on the frame.
Why Geo-Mix Now Has More Pull Than Ad Copy in a Global Account

Same campaigns, same creatives, 22x ROAS spread by region: LATAM 1.31x, Africa 1.04x, NAM 0.41x, MENA 0.25x, EU 0.06x. Single global B2B SaaS account, one 60-day window, geo-mix did all the work.
One global presentation-AI client in the book showed a 22x ROAS spread by region in our 60-day reads. Same campaigns, same creatives. The geo-mix did most of the work:
Nothing in the creative changed across regions. The audience did, and the math followed. In 2026, the geo-mix decision tends to have more pull on global paid programs than the ad copy choice does.
We see this often enough across the book that the first slide in any global account review is now a regional ROAS heatmap. The budget conversation tends to start there. Our paid spend management work starts at the same place: most efficiency work begins with which geos to pause before any creative iteration is worth running.
Chapter 3. The Hidden Version: RevOps
Inside RevOps, the same gap surfaces silently. Across the RevOps stacks we audited this quarter, mostly on prospect and partner accounts coming in for evaluation, every single one was leaking pipeline somewhere. None of those stacks looked broken from the outside.
The dashboards were running. The pipeline numbers reconciled to one decimal place. The leaks sat inside the plumbing, in places nobody on those teams had opened in over a year.
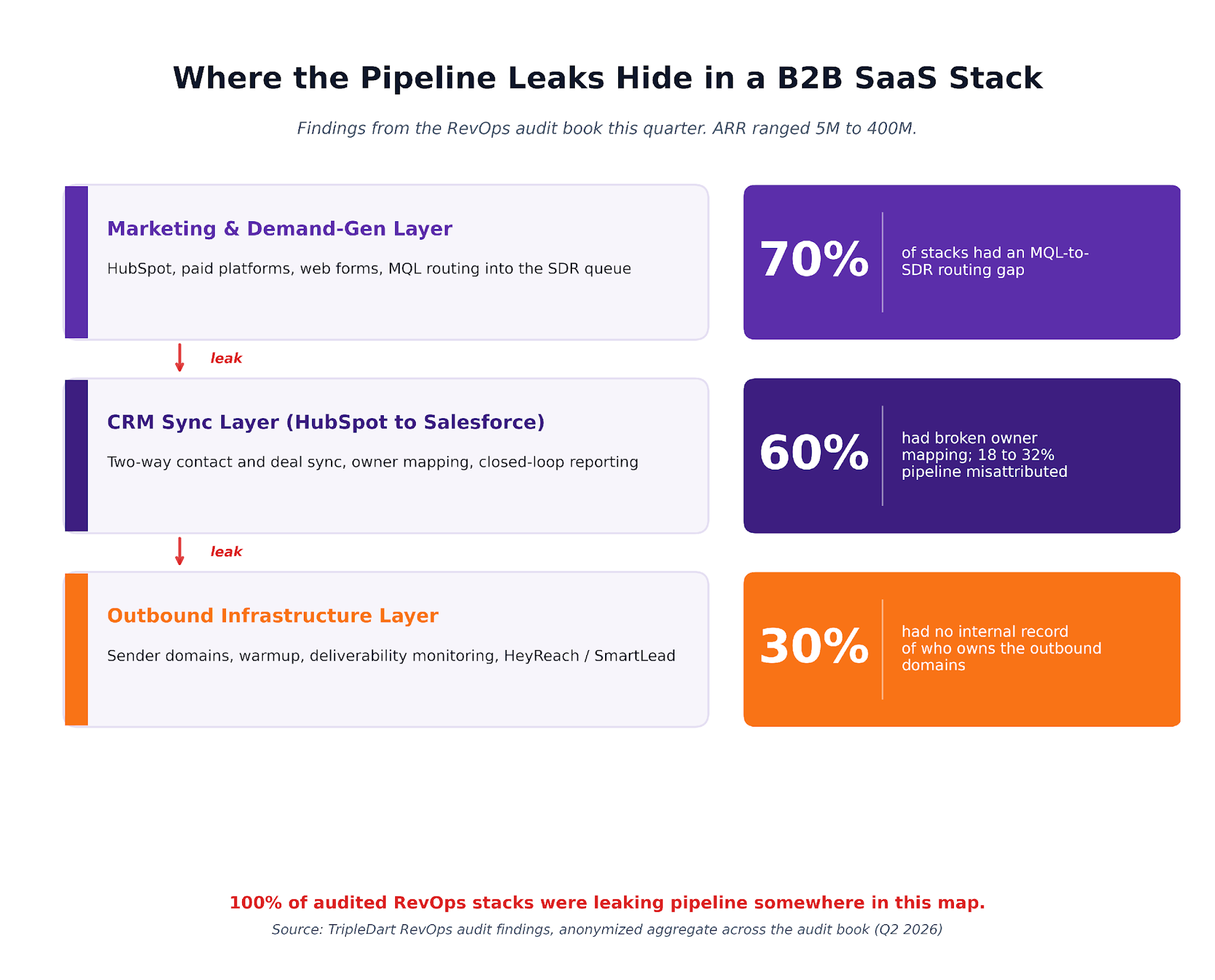
Where the pipeline leaks hide in a B2B SaaS stack: in the marketing and demand-gen layer, 70% of stacks had an MQL-to-SDR routing gap. In the CRM sync layer between HubSpot and Salesforce, 60% had broken owner mapping plus 18 to 32% pipeline misattribution. In the outbound infrastructure layer, 30% had no internal record of who owns the outbound domains. 100% of audited RevOps stacks were leaking pipeline somewhere on this map.
A few headline numbers from the audit book this quarter:
- Average misattribution between Salesforce and HubSpot: 18 to 32%
- ARR range across the audited companies: 5M to 400M
- Stage that predicted cleanliness of the stack: none
Some of the worst leaks sat inside late-stage stacks. The original setup had typically been done years ago by an SDR who has since left the company, and nobody had touched the routing layer since. The dashboards looked fine. The pipeline numbers looked fine. The reality, when we went looking, didn't.
Why a Two-Week Sprint Beats an Open RevOps Retainer
We've productized a two-week attribution audit sprint. Fixed scope, fixed timeline, fixed deliverable.
Average finding inside the window: 18 to 32% of pipeline misattributed between Salesforce and HubSpot. Once corrected, paid media ROI calculations move sharply. The investment case for entire channels frequently flips.
A productized sprint reads better than an open retainer for this kind of work because of the stop point. If the leaks surface inside two weeks, they get corrected. If the stack reads clean, the budget gets redirected to the next move. Either outcome feeds the next planning conversation, the one our revenue operations metrics work is built around.
The Salesforce attribution research summarized in this B2B attribution overview found 41% of marketing organizations don't set up multi-touch attribution until month six or later. That tracks almost exactly with what we keep finding when we open up a live setup.
Classify Inbound Leads Before You Enrich Them
For one data-cataloging client, we deployed a custom LLM prompt inside HubSpot workflows. It classifies inbound leads in real time into four buckets: Service-Aligned, Service-Adjacent, Management-Aligned, Management-Adjacent. A Dual-Fit flag and a default route handle the ambiguous cases.
The result inside the first month: SDRs route in seconds, high-ACV deals fast-track to AEs automatically, and time to deploy was under two weeks.
Worth naming what this replaces:
Most teams we've onboarded recently get there inside the first phase of HubSpot Marketing Hub setup. The classifier has to live inside the workflow layer to fire fast enough.
The Owner-Mapping Bug Hiding Inside Most B2B Stacks
This one tends to sit invisible until somebody goes looking. We've found it in most of the stacks we audited this quarter.
Here's the bug. When Salesforce owners sync into HubSpot, the contact-owner ID HubSpot stores is the Salesforce user ID, where it should be the HubSpot user ID. The two systems present as if they're synced. The IDs are mismatched underneath.
The downstream symptoms are silent. Sequence enrollments fail without alerting anyone. Lead queues route to ghost users. SDRs work from incomplete views. Dashboards keep running because nothing is technically broken, just routed to nowhere.
The correction is a one-time mapping table plus a workflow guardrail that validates the owner ID type before any downstream automation fires. Productivity recovery shows up inside the first week of the fix.
We've added this check to our standing HubSpot audit checklist. We're catching it in roughly 60% of stacks before the audit even begins.
Treat Outbound Domains Like Production Infrastructure
In a chunk of the audits this quarter, the company we were auditing had no internal record of the outbound sender domains, the HeyReach or SmartLead workspaces, or the warmup schedules running underneath both. The original setup had usually been done by an ex-employee, and the documentation tended to leave with them.
Domain reputation is pipeline. When deliverability degrades, MQL flow degrades two months later. Tracing the cause back to a warmup schedule that nobody is monitoring tends to be a slow, frustrating Friday afternoon for whoever is left holding the work.
We now run outbound infrastructure as a managed layer for this category of client. It covers domains, warmup, sender pools, and deliverability monitoring on the same governance cadence as the paid and SEO programs: standing weekly checks, an alert threshold per metric, and a clear owner per domain.
What Has Changed Underneath at TripleDart in 2026
The through-line in our operating model picked up the same pattern we kept seeing in the data. Closer to the work, on shorter loops, with the watching automated. Three changes have stuck across the active book.

How TripleDart has changed underneath in 2026: AI agents on every account, with daily account-health agents on paid, weekly LLM-summarized SEO reads, and Fathom call sentiment feedback within hours. Productized sprints as the entry motion, including a two-week attribution audit, programmatic SEO and GEO sprints, and outbound domain stand-up sprints. Slate as the connective tissue, monitoring rankings and AI citations, surfacing prioritized actions weekly, and powering the research, write, refresh loop.
AI Agents on Every Account, Always Watching
The agents now run across most of the active book. Daily account-health agents on a growing share of paid programs. Weekly LLM-summarized SEO reads for content engagements. Fathom call sentiment plus opportunity classification feeding back to the account team within hours of every client meeting.
The human team still owns the strategy and the calls. The agents handle the watching. Our internal AI SEO agent reads cohort GSC and AIO data on a weekly cadence and surfaces priority pages before the strategy call lands.
Productized Sprints as the Way We Start
The entry motion across most of our work has moved to a sprint-first model. Each sprint runs on fixed scope, fixed timeline, and fixed deliverable. The catalog now covers four common shapes:
Open retainer engagements continue. The entry motion has moved to a sprint-first model that builds shared evidence before we scale spend. It's a closer fit to the cadence the work runs at. It's how most of our SaaS SEO engagements start now.
Slate, Quietly Running in the Background
Slate is our content engineering and visibility platform. It runs in the background of these engagements, monitoring rankings and AI citations across ChatGPT, Claude, Gemini, and Perplexity, surfacing prioritized actions for content teams, and powering the research, write, refresh loop.
The weekly client conversation has moved from "what should we write next?" to "what did Slate flag this week?" The roles split cleanly across the loop:
What This Means If You're Running Marketing for a B2B SaaS Company
The biggest lever we've watched move pipeline in 2026 has been cadence. Channel has tended to come second.
Three questions tend to come up in the planning conversations we've had with CMOs and heads of growth this quarter. They're the same questions we ask ourselves on every account at the start of the week.
On content and SEO. Are the weekly reads picking up the LLM-sourced session signal, or only the Google clicks? Programs reading only the Google clicks tend to be tracking metrics that no longer map cleanly to pipeline. Our SaaS SEO strategy guide walks through what we're now layering into the read.
On paid media. Can the team see when CVR moved on the top three campaigns last week, in hours? When the answer is in days, the detection problem usually sits upstream of the bid problem.
On RevOps. When was the last clean attribution audit on the stack, and who owns each owner-ID mapping today? When the answers come back as "more than 90 days ago" and "nobody is sure," the leak tends to already be inside the numbers.
None of these are gotchas. Most of the time, the answer points to where the next two weeks of work should go.
We're happy to share any of these on request, all anonymized: the audit checklist, the AI lead classification prompt, the daily agent SOPs, the GEO playbook. Get in touch with us here.
We're also running productized sprints and audit engagements across the SaaS content marketing book over the next quarter. We'd rather have a working diagnosis on the table before any retainer conversation. If any of the patterns above sound close to what's running on your side, that's the call to start with.
Frequently Asked Questions
How is this report different from a typical agency benchmark study?
Most public benchmark studies pull from one channel and one method: a survey, a third-party tool's index, or a single dataset. This one pulls from the active client book across SEO, paid media, and RevOps simultaneously, on a single 60-day window. The same operating team reads the data across all three.
The aperture is what makes the difference. We see the same accounts on the SEO dashboard, the paid dashboard, and the RevOps audit. That cross-view is how the cadence pattern surfaced in the first place.
What does "LLM-sourced traffic" mean exactly?
We mean sessions that arrive on the client site with a referrer or click-through signal from ChatGPT, Claude, Perplexity, Gemini, or a Google AI Overview citation.
The mechanism varies by platform. Some pass clean referrers, some pass identifiable user agents, and some require a combination of UTM parameters and citation tracking on the source side. The Averi 2026 AI citation benchmarks report covers the platform-by-platform measurement nuance well.
How do AI account-health agents work in practice?
Each agent reads the account's daily ad-platform data plus the conversion stream from the CRM. It runs an anomaly check against the baseline across four dimensions: pacing against budget, CVR by cohort, search-term spend distribution, and cap breaches.
The agent posts a structured summary into the client Slack channel every morning along with a recommended action queue. The strategist reviews, validates root cause where needed, and makes the optimization call. The watching sits with the agent. The decision sits with the human.
Are productized sprints a fit for every client?
They tend to be a fit when the scope is bounded, the deliverable is clear, and the success criteria can be defined inside two to eight weeks. Attribution audits, programmatic SEO launches, GEO visibility lifts, and outbound domain stand-ups all fit that profile.
Long-running content programs and full-funnel paid management tend to read better with an open retainer and a defined operating cadence. We use sprints as the entry motion now. The retainer follows when the evidence is on the table.
What's the fastest place to start if our cadence feels behind?
A two-week HubSpot audit and an attribution check on the CRM and ad-platform connections tends to surface findings that change the next quarter's investment plan. The work usually pays for itself in the first redirected channel budget.
From there, two adjacent moves cover most of the cadence gap most B2B SaaS programs are sitting with right now: a daily account-health agent on the largest paid program, and a weekly LLM-summarized read on the top 50 organic pages. The rest is an operating-cadence conversation. That's a conversation we're happy to have.
.webp)





